21 Fundamentos Conformal y Optimización Robusta
Marco teórico extendido para convertir incertidumbre conformal en conjuntos robustos de decisión.
Nota editorial: este capítulo conserva material técnico de soporte para tesis, supplement y revisión. Los bloques de código quedan acotados visualmente por defecto; la lectura principal está en el texto, las tablas y las figuras.
Uso IJDS
Teoría compacta del bound: split conformal, presupuesto de robustez y vínculo entre cobertura y factibilidad.
Uso tesis
Fundamentos extendidos para explicar por qué CRPTO combina incertidumbre predictiva y optimización robusta.
Uso supplement
Caveats técnicos, alternativas conformales y lectura de colas cuando el reviewer pide más formalización.
Procedencia: book/chapters/02-glossary/02c-uncertainty-conformal.qmd
21.1 Incertidumbre y Predicción Conformal
La cuantificación de incertidumbre es una de las piezas más críticas — y frecuentemente ignoradas — en la modelación de riesgo crediticio. Un modelo que produce una estimación puntual de \(\hat{p} = 0.15\) para la probabilidad de default de un préstamo no transmite si esa estimación es confiable o altamente incierta. En un portafolio de miles de préstamos, tomar decisiones de asignación basadas exclusivamente en puntos estimados sin considerar su incertidumbre conduce a portafolios frágiles que se deterioran bajo condiciones adversas.
Esta sección introduce los fundamentos teóricos de la cuantificación de incertidumbre, con énfasis particular en la predicción conformal — un marco que ofrece garantías matemáticas de cobertura sin requerir supuestos distribucionales sobre los datos.
21.1.1 Incertidumbre Aleatórica vs Epistémica
La incertidumbre en las predicciones de un modelo tiene dos fuentes fundamentalmente distintas:
Incertidumbre aleatórica (irreducible): Es la variabilidad inherente al fenómeno observado. Proviene de la estocasticidad intrínseca del proceso generador de datos y no puede eliminarse recopilando más datos ni mejorando el modelo. En riesgo crediticio, la incertidumbre aleatórica refleja que dos prestatarios con exactamente las mismas características observables pueden tener outcomes distintos: uno paga y el otro entra en default. Esto ocurre porque existen factores no observados — eventos de salud, pérdida de empleo, decisiones personales — que afectan el repago pero no están capturados en las features del modelo.
Incertidumbre epistémica (reducible): Es la incertidumbre que surge de la limitación del conocimiento del modelo. Se debe a datos insuficientes, especificación incorrecta del modelo, o regiones del espacio de features con poca representación en el conjunto de entrenamiento. A diferencia de la aleatórica, esta incertidumbre puede reducirse con más datos o un modelo mejor especificado.
Considérese un préstamo de grado G con un historial crediticio muy corto. La incertidumbre sobre su PD tiene ambos componentes:
- Aleatórica: Aún conociendo perfectamente todas las características del prestatario, existe variabilidad inherente en si entrará o no en default.
- Epistémica: Dado que los préstamos grado G con historial corto son relativamente escasos en el conjunto de entrenamiento, el modelo tiene menos evidencia para estimar su PD con precisión. Con más datos de prestatarios similares, este componente se reduciría.
En la práctica, los intervalos conformales capturan ambas fuentes de incertidumbre simultáneamente, sin necesidad de descomponerlas explícitamente.
En la modelación Bayesiana, la incertidumbre epistémica se captura a través de la distribución posterior sobre los parámetros del modelo, mientras que la aleatórica se captura a través de la distribución predictiva posterior. Los métodos conformales, en cambio, producen intervalos que absorben ambas fuentes de forma agnóstica — no requieren especificar un prior ni una verosimilitud, lo que los hace especialmente atractivos para aplicaciones regulatorias donde la transparencia y la ausencia de supuestos son valoradas.
21.1.2 Intervalos de Predicción vs Intervalos de Confianza
Una confusión frecuente en la práctica estadística — y particularmente peligrosa en gestión de riesgo — es la diferencia entre intervalos de confianza e intervalos de predicción. Aunque ambos producen rangos numéricos, cuantifican objetos fundamentalmente distintos.
Intervalo de confianza para un parámetro \(\theta\) al nivel \(1 - \alpha\): Es un rango \([\hat{\theta}_L, \hat{\theta}_U]\) tal que, bajo muestreo repetido:
\[ P\left(\theta \in [\hat{\theta}_L, \hat{\theta}_U]\right) \geq 1 - \alpha \]
El intervalo de confianza cuantifica la incertidumbre sobre un parámetro poblacional (por ejemplo, la tasa de default promedio de un segmento). Se estrecha con más datos porque la estimación del parámetro mejora.
Intervalo de predicción para una nueva observación \(Y_{n+1}\) al nivel \(1 - \alpha\): Es un rango \([L(X_{n+1}), U(X_{n+1})]\) tal que:
\[ P\left(Y_{n+1} \in [L(X_{n+1}), U(X_{n+1})]\right) \geq 1 - \alpha \]
El intervalo de predicción cuantifica la incertidumbre sobre una observación futura individual. Incluye tanto la incertidumbre sobre el parámetro (epistémica) como la variabilidad inherente del outcome (aleatórica), por lo que es necesariamente más ancho que el intervalo de confianza correspondiente.
| Propiedad | Intervalo de Confianza | Intervalo de Predicción |
|---|---|---|
| Objeto cuantificado | Parámetro poblacional \(\theta\) | Observación futura \(Y_{n+1}\) |
| Fuentes de incertidumbre | Solo epistémica | Epistémica + aleatórica |
| Comportamiento con \(n \to \infty\) | Se estrecha a cero | Converge a un ancho mínimo > 0 |
| Uso en riesgo crediticio | Tasa de default de un segmento | PD de un préstamo individual |
| Error común | Usar como si fuera predicción | Ignorar la componente aleatórica |
En muchos modelos de riesgo crediticio en producción, se reportan intervalos de confianza sobre la PD media de un segmento como si fueran intervalos de predicción para préstamos individuales. Esto subestima sistemáticamente la incertidumbre: un intervalo de confianza al 95% para la PD media de grado B podría ser [0.11, 0.13], mientras que el intervalo de predicción individual correcto podría ser [0.02, 0.35]. La diferencia es crucial para la gestión de portafolio y la determinación de provisiones bajo IFRS9.
En este proyecto, todos los intervalos generados son intervalos de predicción — cuantifican la incertidumbre sobre la PD de cada préstamo individual, no sobre parámetros promedio de segmentos.
21.1.3 Fundamentos de la Predicción Conformal
La predicción conformal, introducida por Vovk, Gammerman y Shafer (Vovk et al., 2005), es un marco teórico para construir intervalos de predicción con garantías finitas de cobertura sin asumir una distribución paramétrica específica para los datos. Esta propiedad la distingue fundamentalmente de los intervalos paramétricos (que requieren supuestos distribucionales) y los intervalos bootstrap (que son asintóticos y pueden fallar en muestras finitas).
El supuesto de intercambiabilidad
El único supuesto teórico requerido por la predicción conformal es la intercambiabilidad (exchangeability) de los datos. Una secuencia de variables aleatorias \((Z_1, Z_2, \ldots, Z_n)\) es intercambiable si su distribución conjunta es invariante bajo cualquier permutación:
\[ P(Z_1, Z_2, \ldots, Z_n) = P(Z_{\pi(1)}, Z_{\pi(2)}, \ldots, Z_{\pi(n)}) \quad \forall \pi \in S_n \]
donde \(S_n\) es el grupo de todas las permutaciones de \(\{1, 2, \ldots, n\}\).
La intercambiabilidad es estrictamente más débil que el supuesto i.i.d. (independiente e idénticamente distribuido): todas las secuencias i.i.d. son intercambiables, pero no toda secuencia intercambiable es i.i.d. Por ejemplo, un muestreo sin reemplazo de una urna finita produce secuencias intercambiables pero no independientes.
En este proyecto, los splits temporales (train/calibración/test) violan la intercambiabilidad estricta porque la distribución de préstamos puede cambiar con el tiempo (concept drift). Sin embargo, la predicción conformal es notablemente robusta en la práctica: incluso bajo desviaciones moderadas de la intercambiabilidad, la cobertura empírica permanece cercana a la garantía teórica. Cuando el supuesto se rompe de forma sistemática, la teoría ofrece correcciones: la predicción conformal ponderada bajo covariate shift (Tibshirani et al., 2019) reescala los scores por la razón de densidades entre calibración y test, y la inferencia conformal adaptativa (Gibbs & Candès, 2021) ajusta el nivel en línea período a período. CRPTO no aplica estas correcciones de forma activa — prefiere documentar el shift empíricamente vía backtesting temporal y stress sintético (Tablas A6/A11) —, pero su existencia explica por qué la cobertura empírica se mantiene cercana al objetivo pese al carácter temporal del split. En el cierre final OOT (2018–2020), la variante promovida score_decile_mondrian alcanza 92.97% de cobertura al 90% con cobertura mínima por grupo de 91.90%, lo que indica un conservadurismo útil sin perder legibilidad regulatoria del baseline.
La garantía de cobertura
La idea importante no es memorizar el teorema, sino entender qué promete el método: si pedimos cobertura del 90%, el procedimiento está construido para que, en promedio, el valor real quede dentro del intervalo alrededor de 9 de cada 10 veces. En nuestro conjunto de calibración, que tiene 237,584 préstamos, esa garantía teórica se vuelve muy precisa porque hay mucha evidencia empírica para fijar el umbral conformal.
- Si el intervalo sale muy estrecho, puede perder cobertura.
- Si sale muy ancho, cubre más, pero aporta menos para decidir.
- La gracia de conformal es que ofrece un equilibrio práctico: cobertura controlada sin asumir una distribución paramétrica exacta.
Esta garantía es marginal — se cumple en promedio sobre la distribución conjunta de los datos de calibración y el nuevo punto de test. No garantiza cobertura condicional para cada subgrupo de préstamos (para eso se necesita el enfoque Mondrian, descrito en sec-mondrian-primer).
La utilidad de la predicción conformal no es solo teórica. En un ensayo controlado aleatorizado y pre-registrado, dar a personas conjuntos de predicción conformales mejoró de forma estadísticamente significativa la calidad de sus decisiones frente a conjuntos de tamaño fijo con la misma cobertura nominal (Cresswell et al., 2024): el ancho del intervalo comunica incertidumbre y ofrece alternativas, exactamente la señal que un comité de riesgo necesita para decidir sobre un préstamo dudoso. Ese es el puente conceptual de todo el proyecto: el intervalo conformal no es un adorno diagnóstico, sino el objeto que vuelve la decisión de cartera auditable y mejor informada que una PD puntual.
Scores de nonconformidad
El concepto central del framework conformal es el score de nonconformidad (nonconformity score), denotado \(s(x, y)\). Este score mide qué tan “inusual” o “no conforme” es una observación \((x, y)\) respecto al patrón aprendido por el modelo. A mayor score, más atípica es la observación.
Para regresión (y para la estimación de intervalos de PD), el score más común es el residuo absoluto:
\[ s_i = |y_i - \hat{f}(x_i)| \]
donde \(\hat{f}(x_i)\) es la predicción del modelo para la observación \(i\). En nuestro caso, \(\hat{f}(x_i)\) es la PD calibrada y \(y_i \in \{0, 1\}\) es el indicador binario de default.
Otros scores de nonconformidad incluyen:
- Residuo escalado: \(s_i = \frac{|y_i - \hat{f}(x_i)|}{\hat{\sigma}(x_i)}\), donde \(\hat{\sigma}(x_i)\) es una estimación local de dispersión. Produce intervalos de ancho variable (heteroscedásticos).
- Residuo normalizado: \(s_i = \frac{|y_i - \hat{f}(x_i)|}{\sqrt{\hat{f}(x_i)(1 - \hat{f}(x_i))}}\), que normaliza por la varianza binomial. En nuestro código, esto corresponde al parámetro
scaled_scores=True. - Score CQR: Basado en cuantiles condicionales (ver
sec-cqr).
La elección del score afecta la eficiencia (ancho de los intervalos) pero no la validez (garantía de cobertura). Cualquier función de score produce intervalos con cobertura válida; scores más sofisticados producen intervalos más estrechos.
21.1.4 Split Conformal
El Split Conformal (o Inductive Conformal Prediction) es la variante más práctica y computacionalmente eficiente de la predicción conformal. Su lógica puede resumirse sin entrar en demostraciones:
- Entrenar primero el modelo base con un conjunto de datos histórico.
- Reservar un conjunto de calibración que el modelo no haya visto durante el entrenamiento.
- Medir en calibración qué tan grandes son los errores típicos del modelo.
- Usar ese error típico como colchón para construir un intervalo alrededor de cada nueva predicción.
En términos intuitivos, Split Conformal toma la predicción puntual del modelo y le agrega una banda de seguridad aprendida a partir del comportamiento real del modelo en un conjunto separado. Si el modelo viene fallando por márgenes grandes, la banda se ensancha. Si el modelo viene siendo estable, la banda se hace más corta.
Para PD, además, esa banda siempre se recorta al rango válido de probabilidades, es decir, entre 0 y 1.
Nótese que el procedimiento Split Conformal requiere una sola pasada de predicción sobre el conjunto de calibración y el cálculo de un único cuantil. No hay refitting del modelo, no hay bootstrapping, no hay simulación Monte Carlo. Esto hace que sea extremadamente eficiente computacionalmente — en nuestro pipeline, generar intervalos conformales para 276,869 préstamos de test toma menos de un segundo una vez que el modelo está entrenado.
Requisito del conjunto de calibración separado
Un aspecto fundamental del Split Conformal es que el conjunto de calibración debe ser estrictamente independiente del conjunto de entrenamiento. Si se usan los mismos datos para entrenar el modelo y para calcular los scores de nonconformidad, los scores serán optimistamente pequeños (el modelo se ajusta bien a sus propios datos de entrenamiento) y los intervalos resultantes serán demasiado estrechos, violando la garantía de cobertura.
En nuestro proyecto, la separación se garantiza mediante splits temporales:
| Conjunto | Período | Uso |
|---|---|---|
| Train | 2007-06 a 2017-03 | Entrenamiento del modelo CatBoost |
| Calibración | 2017-03 a 2017-12 | Cálculo de scores conformales (\(n = 237{,}584\)) |
| Test (OOT) | 2018-01 a 2020-09 | Evaluación de cobertura (\(n = 276{,}869\)) |
Implementación con MAPIE 1.3.0
La biblioteca MAPIE (Model Agnostic Prediction Interval Estimator) (Taquet et al., 2022) provee una implementación robusta y bien mantenida del framework conformal para Python. La versión 1.3.0 introdujo una API renovada con clases dedicadas.
Para intervalos de PD, el flujo de trabajo con SplitConformalRegressor es:
- Envolver el clasificador CatBoost en un
ProbabilityRegressorque exponepredict()retornando \(P(\text{default})\). - Instanciar el conformal regressor con
prefit=Truey el nivel de confianza deseado. - Conformizar sobre el conjunto de calibración con
conformalize(X_cal, y_cal). - Predecir intervalos sobre nuevos datos con
predict_interval(X_test).
La versión 1.3.0 de MAPIE reemplazó completamente la API anterior. Los cambios clave son:
SplitConformalRegressorreemplaza aMapieRegressorSplitConformalClassifierreemplaza aMapieClassifier- El flujo es
fit()→conformalize()→predict_interval() - El nivel de confianza se específica en
__init__conconfidence_level(noalphaenpredict) - Los modelos pre-entrenados usan
prefit=True(nocv="prefit")
21.1.5 Predicción Conformal Mondrian
La garantía de cobertura de la eq-coverage-guarantee es marginal — se cumple en promedio sobre toda la distribución. Esto significa que si un modelo tiene 90% de cobertura global, podría tener 98% de cobertura para préstamos grado A y solo 72% para préstamos grado G. En gestión de riesgo crediticio, esta heterogeneidad es inaceptable: los préstamos de alto riesgo son precisamente los que más necesitan intervalos confiables.
La predicción conformal Mondrian (Boström et al., 2021) resuelve este problema proporcionando garantías de cobertura condicionales por grupo.
Formulación formal
Sea \(\mathcal{G} = \{g_1, g_2, \ldots, g_K\}\) una partición del espacio de observaciones en \(K\) grupos disjuntos. La predicción conformal Mondrian construye cuantiles conformales separados para cada grupo:
\[ \hat{q}_\alpha^{(k)} = \text{Quantile}\left(\{s_i : G(X_i) = g_k, \; i \in \mathcal{D}_\text{cal}\}, \; \frac{\lceil (n_k + 1)(1-\alpha) \rceil}{n_k}\right) \]
donde \(n_k = |\{i \in \mathcal{D}_\text{cal} : G(X_i) = g_k\}|\) es el número de observaciones de calibración en el grupo \(k\), y \(G(X_i)\) es la función que asigna la observación \(i\) al grupo correspondiente.
El intervalo para una nueva observación en el grupo \(g_k\) es:
\[ C_\alpha^{(k)}(X_{n+1}) = \left[\hat{f}(X_{n+1}) - \hat{q}_\alpha^{(k)}, \; \hat{f}(X_{n+1}) + \hat{q}_\alpha^{(k)}\right] \]
Garantía de cobertura condicional por grupo
Bajo intercambiabilidad dentro de cada grupo, la predicción Mondrian satisface:
\[ P\left(Y_{n+1} \in C_\alpha^{(k)}(X_{n+1}) \mid G(X_{n+1}) = g_k\right) \geq 1 - \alpha, \quad \forall k \in \{1, \ldots, K\} \]
Esta garantía es estrictamente más fuerte que la garantía marginal: cobertura condicional por grupo implica cobertura marginal, pero no al revés.
¿Por qué el grado de riesgo como partición?
La elección de la variable de partición Mondrian es crítica. En riesgo crediticio, el grado de riesgo (A–G en Lending Club) es una partición natural por varias razones:
- Grupos disjuntos por diseño: Cada préstamo pertenece a exactamente un grado, cumpliendo el requisito de partición.
- Heterogeneidad de riesgo: Las tasas de default varían dramáticamente entre grados (véase
tbl-credit-grades), por lo que el modelo tiene diferentes niveles de incertidumbre por grupo. - Relevancia regulatoria: Las matrices de transición y las reservas IFRS9 se calculan por grado, alineando los intervalos conformales con el framework regulatorio existente.
- Tamaño muestral adecuado: Incluso el grado más pequeño (G) tiene miles de observaciones en calibración, asegurando cuantiles estables.
Además del grado, nuestro proyecto implementa otras particiones Mondrian: por deciles de score (score_decile_mondrian) y por grado cruzado con bandas de score (grade_x_scoreband_mondrian). Las particiones más finas producen intervalos más adaptativos pero requieren más datos de calibración por celda. Cuando una celda tiene pocos datos (debajo de un umbral min_group_size), se aplica fallback al cuantil del grado o al cuantil global.
La jerarquía correcta en el proyecto es esta:
gradesigue siendo la partición natural e interpretable que justifica por qué Mondrian tiene sentido en crédito;score_decile_mondrianes la variante final objetivamente promovida por el benchmark/reopen conformal;grade_x_scoreband_mondrianfunciona como prueba de granularidad adicional, no como winner final.
Es decir: el grado no desaparece, pero ya no compite como campeón final. Su rol es estructural y explicativo; el winner único del proyecto es score_decile_mondrian.
Ancho diferencial por grado
Una consecuencia directa del enfoque Mondrian es que los intervalos tienen ancho diferente por grado. Préstamos de grado A (bajo riesgo, PD bien calibrada) obtienen intervalos estrechos, mientras que préstamos de grado G (alto riesgo, mayor incertidumbre) obtienen intervalos más anchos. Esto es deseable porque refleja la realidad: hay más incertidumbre sobre préstamos de alto riesgo.
En términos simples: si el modelo se equivoca más en un grupo, ese grupo recibe un intervalo más ancho. Eso es justamente lo que queremos en Lending Club: más prudencia donde el riesgo es menos estable.
21.1.6 Regresión Cuantílica Conformalizada (CQR)
La Regresión Cuantílica Conformalizada (CQR), propuesta por Romano, Patterson y Candès (Romano et al., 2019), combina la flexibilidad de la regresión cuantílica con las garantías de la predicción conformal. A diferencia del Split Conformal estándar que produce intervalos de ancho constante (para un mismo grupo), CQR produce intervalos de ancho adaptativo que varían observación por observación.
Idea central
CQR opera en dos etapas:
Etapa 1 — Entrenamiento de regresión cuantílica: Se entrena un modelo de regresión cuantílica que produce estimaciones de los cuantiles inferior \(\hat{q}_{\alpha/2}(x)\) y superior \(\hat{q}_{1-\alpha/2}(x)\) condicionales en \(x\).
Etapa 2 — Conformización: Se define un score de nonconformidad que mide cuánto se extiende la observación real fuera del intervalo cuantílico estimado:
\[ s_i = \max\left(\hat{q}_{\alpha/2}(X_i) - Y_i, \; Y_i - \hat{q}_{1-\alpha/2}(X_i)\right) \]
Se calcula el cuantil conformal \(\hat{Q}_\alpha\) de estos scores sobre el conjunto de calibración, y el intervalo final es:
\[ C_\alpha^{\text{CQR}}(X_{n+1}) = \left[\hat{q}_{\alpha/2}(X_{n+1}) - \hat{Q}_\alpha, \; \hat{q}_{1-\alpha/2}(X_{n+1}) + \hat{Q}_\alpha\right] \]
Ventajas sobre Split Conformal estándar
La principal ventaja de CQR es que hereda la estructura de los cuantiles condicionales: si la varianza condicional de \(Y|X = x\) varía con \(x\) (heteroscedasticidad), los intervalos CQR serán más estrechos donde la varianza es baja y más anchos donde es alta, todo sin sacrificar la garantía de cobertura.
En el contexto de PD, esto significa que un préstamo con features que lo ubican en una región de alta certeza del modelo obtendrá un intervalo más estrecho que uno en una región de baja certeza, dentro del mismo grado. El enfoque Mondrian + CQR combinaría ambas ventajas: adaptación entre grupos (Mondrian) y adaptación dentro de grupos (CQR).
En la implementación actual, el pipeline conserva dos capas conceptuales distintas: grade como baseline interpretativo y score_decile_mondrian como winner final seleccionado. CQR está disponible como benchmark alternativo. La elección del winner final no se apoya en “usar grades por defecto”, sino en un benchmark objetivo que mostró que score_decile_mondrian entrega mejor combinación de cobertura, cobertura mínima por grupo y anchura útil sobre OOT. El rol de grade sigue siendo necesario porque captura la semántica económica y regulatoria que motiva Mondrian desde el dominio de crédito.
21.1.7 Tradeoff entre Cobertura y Ancho
Los dos criterios fundamentales para evaluar intervalos de predicción son la cobertura y el ancho (también llamado sharpness). Existe una tensión inherente entre ambos:
- Cobertura (\(1 - \alpha\)): Fracción de observaciones cuyo valor verdadero cae dentro del intervalo predicho. Mayor cobertura requiere intervalos más amplios.
- Ancho (\(w = U - L\)): Diferencia entre el límite superior e inferior del intervalo. Intervalos más estrechos son más informativos pero arriesgan cobertura insuficiente.
El intervalo trivial \([0, 1]\) para PD tiene cobertura perfecta (100%) pero ancho máximo (1.0) — no aporta ninguna información. El desafío es construir intervalos lo más estrechos posible sujeto a la restricción de cobertura.
Si dos métodos alcanzan prácticamente la misma cobertura, preferimos el que produzca intervalos más estrechos. Esa es la idea operativa de eficiencia en este capítulo: misma seguridad, menor ambigüedad para la decisión.
Efecto de \(\alpha\) sobre cobertura y ancho
Al variar \(\alpha\), se traza una curva de Pareto entre cobertura y ancho:
| Nivel \(\alpha\) | Cobertura objetivo | Comportamiento del ancho |
|---|---|---|
| 0.20 | 80% | Intervalos estrechos, menor protección |
| 0.10 | 90% | Balance habitual en la práctica |
| 0.05 | 95% | Intervalos más anchos, mayor protección |
| 0.01 | 99% | Intervalos muy anchos, máxima protección |
Es posible que un método logre excelente cobertura marginal (promedio global) pero falle en subgrupos específicos. En riesgo crediticio, la cobertura condicional por grado es más relevante que la marginal: un banco necesita saber que los intervalos son confiables para cada segmento de riesgo, no solo en promedio. El enfoque Mondrian aborda precisamente este problema al garantizar cobertura condicional por grupo.
En nuestros experimentos de alpha sweep, el enfoque Mondrian identifica 25,625 préstamos elegibles (9.3% del test set) para reclasificación a alpha = 0.10, mientras que el enfoque global no identifica ninguno al mismo nivel — demostrando que la granularidad condicional es operativamente superior.
Escalera de validez conformal
La bibliografía reciente obliga a separar con cuidado qué tipo de validez se está reclamando. En CRPTO, la garantía operacional principal es marginal o Mondrian por partición definida; no es cobertura condicional exacta para cada perfil individual. Esa precisión protege el paper y fortalece la tesis.
| Nivel | Qué permite decir | Dónde queda CRPTO |
|---|---|---|
| Marginal split conformal | La cobertura promedio sobre la población exchangeable alcanza el objetivo (Angelopoulos & Bates, 2023; Vovk et al., 2005). | Base estadística de los intervalos. |
| Mondrian / group conformal | La cobertura se audita por particiones predefinidas (Boström et al., 2021; Gibbs et al., 2025). | Lectura natural por grade y score decile. |
| Cobertura ponderada o localizada | La cobertura se adapta a pesos, vecindarios o grupos seleccionados (Barber et al., 2023; Guan, 2023; Jonkers et al., 2024). | Diagnóstico/future work, no método promovido. |
| Multi-distribución | Se controla validez bajo varias fuentes o ambientes (Y. Liu et al., 2024; Yang & Jin, 2026). | A23 como stress read-only. |
| Online/adaptativa | El nivel se ajusta secuencialmente ante drift (Gibbs & Candès, 2021; T. Liu et al., 2026). | A24 como replay OOT, no despliegue live. |
Escalera de decisión conformal
También conviene distinguir si la incertidumbre conformal se queda en una predicción o si entra a una decisión. La tesis debe presentar CRPTO como una posición intermedia: más fuerte que graficar intervalos después del modelo, más conservadora que reentrenar todo end-to-end.
| Escalón | Uso de la incertidumbre | Ejemplo en la literatura | Lectura para CRPTO |
|---|---|---|---|
| Intervalo descriptivo | Reporta incertidumbre, pero no cambia la decisión. | Conformal credit scoring ordinal (Kawasumi et al., 2026). | Vecino de dominio, no sustituto. |
| Conjunto de incertidumbre | El intervalo define el peor caso del optimizador. | CP + robust optimization (Johnstone & Cox, 2021; Patel et al., 2024). | Núcleo CRPTO. |
| Control robusto de pérdida | Certifica una pérdida o propiedad decisional. | CRC y conformal robustness control (Angelopoulos, Bates, et al., 2024; Hu et al., 2026). | Extensión natural. |
| Selección de modelo/decisión | El certificado escoge entre modelos o decisiones. | CROM, CREDO y CREME (Bao et al., 2025; Zhou et al., 2025; Zhou & Zhu, 2026). | V2 posible, no selector del champion actual. |
| Entrenamiento end-to-end | El modelo aprende con pérdida downstream. | SPO+ y DFL robusto (Elmachtoub & Grigas, 2022; Schutte et al., 2024). | Comparador A19; cambia el artefacto predictivo. |
Métricas de evaluación integral
Para evaluar intervalos conformales de forma integral, se utilizan las siguientes métricas:
PICP (Prediction Interval Coverage Probability): Cobertura empírica, que debe ser \(\geq 1 - \alpha\).
\[ \text{PICP} = \frac{1}{n_\text{test}} \sum_{i=1}^{n_\text{test}} \mathbb{1}\left[Y_i \in [L_i, U_i]\right] \]
MPIW (Mean Prediction Interval Width): Ancho promedio de los intervalos.
\[ \text{MPIW} = \frac{1}{n_\text{test}} \sum_{i=1}^{n_\text{test}} (U_i - L_i) \]
NMPIW (Normalized MPIW): Ancho normalizado por el rango de la variable respuesta, que permite comparar entre escalas.
\[ \text{NMPIW} = \frac{\text{MPIW}}{Y_\text{max} - Y_\text{min}} \]
Un método conformal ideal maximiza PICP (cumpliendo \(\geq 1 - \alpha\)) y minimiza MPIW simultáneamente.
21.1.8 Comparación con Alternativas
Para contextualizar las ventajas de la predicción conformal, comparamos con los métodos alternativos más utilizados para cuantificar incertidumbre en modelos de riesgo crediticio:
| Método | Garantía de cobertura | Supuestos distribucionales | Costo computacional | Adaptabilidad |
|---|---|---|---|---|
| Bootstrap | Asintótica | Ninguno explícito | Alto (\(B\) refits) | Baja |
| Bayesiano | Subjetiva (prior-dependent) | Verosimilitud + prior | Muy alto (MCMC) | Alta |
| Conformal | Finita, exacta | Intercambiabilidad | Bajo (1 cuantil) | Media |
| Venn-Abers | Multiprobabilística | Intercambiabilidad | Bajo | Baja |
Bootstrap: Requiere \(B\) (típicamente 100–1000) re-entrenamientos del modelo. Sus intervalos son asintóticos — la cobertura nominal solo se alcanza cuando \(n \to \infty\). En muestras finitas, puede sub-cubrir significativamente, especialmente en las colas de la distribución.
Métodos Bayesianos (BMA): Proporcionan la distribución posterior predictiva completa, pero requieren especificar un prior y una verosimilitud. La calidad de los intervalos depende críticamente de que estos supuestos sean correctos. En nuestras comparaciones, BMA se acerca a la cobertura nominal pero con intervalos materialmente más anchos que el winner conformal final. En el stack vigente, score_decile_mondrian conserva una cobertura empírica superior al 92% al 90% nominal y lo hace con una banda más útil para decisión que los baselines bayesianos simples evaluados en el proyecto.
Predicción conformal: Ofrece el mejor balance entre garantía teórica, eficiencia computacional y ausencia de supuestos. Su principal limitación es que la garantía es marginal (sin Mondrian) y requiere un conjunto de calibración holdout que “pierde” datos para el entrenamiento.
Venn-Abers: Produce intervalos multiprobabilísticos con calibración automática (Vovk & Petej, 2014). Es complementario a la predicción conformal y se usa en este proyecto como método de calibración.
21.1.9 Referencias Clave
Los fundamentos teóricos presentados en esta sección se basan en los siguientes trabajos:
Vovk, Gammerman y Shafer (Vovk et al., 2005): La monografía fundacional de la predicción conformal. Establece el marco teórico completo, incluyendo el teorema de cobertura, las variantes transductiva e inductiva, y las conexiones con la teoría algorítmica de la aleatoriedad. Lectura esencial para la comprensión profunda del framework.
Romano, Patterson y Candès (Romano et al., 2019): Introduce CQR (Conformalized Quantile Regression), que combina regresión cuantílica con conformalización para producir intervalos adaptativos. Este trabajo demostró que la predicción conformal puede ser simultáneamente válida y sharp (eficiente en ancho).
Angelopoulos y Bates (Angelopoulos & Bates, 2023): Una introducción tutorial moderna y accesible a la predicción conformal, publicada en Foundations and Trends in Machine Learning. Cubre Split Conformal, CQR, conjuntos de predicción para clasificación, y extensiones recientes. Recomendada como primer punto de entrada.
Boström et al. (Boström et al., 2021): Formaliza las distribuciones predictivas conformales Mondrian con garantías de cobertura condicional por grupo. Es la base teórica directa de nuestro enfoque de partición por grado crediticio.
Angelopoulos, Barber y Bates (Angelopoulos, Barber, et al., 2024): Monografía moderna que sistematiza los fundamentos teóricos de la predicción conformal (intercambiabilidad, cobertura marginal/condicional, scores, extensiones a control de riesgo). Es la referencia teórica de cabecera para situar el
thm-conformal-feasibilitydentro del marco general.Guan (Guan, 2023): Propone localized conformal prediction, un marco que generaliza la conformalización ponderando localmente los scores de calibración. Es el complemento adaptativo natural a Mondrian: donde Mondrian particiona en grupos discretos (grados), la versión localizada pondera de forma continua en el espacio de features.
Procedencia: book/chapters/02-glossary/02d-optimization-or.qmd
21.2 Optimización e Investigación de Operaciones
La investigación de operaciones (OR) proporciona el marco matemático para tomar decisiones óptimas bajo restricciones. En riesgo crediticio, esto se traduce en preguntas como: ¿a qué préstamos asignar capital para maximizar retorno manteniendo el riesgo agregado bajo control? Esta sección presenta los fundamentos de optimización necesarios para entender el pipeline de este proyecto, desde la programación lineal hasta la optimización robusta con conjuntos de incertidumbre conformales.
21.2.1 Programación Lineal (LP)
La Programación Lineal es la forma más fundamental de optimización matemática. Un problema de LP consiste en maximizar (o minimizar) una función objetivo lineal sujeta a restricciones lineales de igualdad y desigualdad.
Ecuación interpretada
\[ \max_{\mathbf{x}} \; \mathbf{c}^{\top}\mathbf{x} \quad \text{s.a.} \quad A\mathbf{x}\leq\mathbf{b}, \; \mathbf{x}\geq 0 \]
Lectura en este proyecto: elegir cuánto capital asignar a cada préstamo para empujar el retorno esperado hacia arriba sin violar presupuesto, concentración ni tolerancia agregada al riesgo. La ecuación importa menos como símbolo abstracto y más como traducción formal de una pregunta de comité: qué financiar y cuánto.
Forma Estándar
Un LP en forma estándar se escribe como:
\[ \begin{aligned} \max_{\mathbf{x}} \quad & \mathbf{c}^\top \mathbf{x} \\ \text{s.a.} \quad & A\mathbf{x} \leq \mathbf{b} \\ & \mathbf{x} \geq \mathbf{0} \end{aligned} \]
donde:
- \(\mathbf{x} \in \mathbb{R}^n\) es el vector de variables de decisión (en nuestro caso, la fracción de capital asignada a cada préstamo),
- \(\mathbf{c} \in \mathbb{R}^n\) es el vector de costos u objetivo (retornos esperados netos de pérdida),
- \(A \in \mathbb{R}^{m \times n}\) es la matriz de restricciones,
- \(\mathbf{b} \in \mathbb{R}^m\) es el vector de recursos o límites de las restricciones.
Conceptos Clave
- Región factible: El conjunto de todos los \(\mathbf{x}\) que satisfacen simultáneamente todas las restricciones. En LP, esta región es un poliedro convexo (la intersección de semiespacios).
- Solución óptima: Un punto \(\mathbf{x}^*\) en la región factible que alcanza el valor máximo (o mínimo) de la función objetivo. El teorema fundamental de la programación lineal garantiza que, si existe una solución óptima finita, al menos una se encuentra en un vértice del poliedro.
- Infactibilidad: Si las restricciones son contradictorias (no existe ningún \(\mathbf{x}\) que las satisfaga simultáneamente), el problema es infactible.
- No-acotamiento: Si la función objetivo puede crecer indefinidamente dentro de la región factible, el problema es no acotado.
- Dualidad: Todo LP tiene un problema dual asociado. Si el primal maximiza, el dual minimiza. El teorema de dualidad fuerte establece que, si ambos problemas son factibles, sus valores óptimos coinciden.
En este proyecto, el LP de asignación de portafolio tiene la forma:
- Variables: \(x_i \in [0, 1]\) = fracción del préstamo \(i\) que se financia.
- Objetivo: maximizar retorno esperado neto = \(\sum_i x_i \cdot \text{monto}_i \cdot (\text{tasa}_i - \text{PD}_i \cdot \text{LGD}_i)\).
- Restricciones: presupuesto total, PD promedio del portafolio \(\leq\) umbral, concentración máxima por préstamo.
El LP se resuelve en milisegundos con solvers modernos, lo que permite explorar miles de escenarios de política.
21.2.2 Programación Lineal Entera Mixta (MILP)
En muchos problemas reales, algunas decisiones son discretas: financiar o no financiar un préstamo, abrir o cerrar una sucursal, seleccionar \(k\) de \(n\) candidatos. Cuando las variables de decisión incluyen tanto continuas como enteras (típicamente binarias), el problema se convierte en un MILP.
\[ \begin{aligned} \max_{\mathbf{x}, \mathbf{y}} \quad & \mathbf{c}^\top \mathbf{x} + \mathbf{d}^\top \mathbf{y} \\ \text{s.a.} \quad & A\mathbf{x} + B\mathbf{y} \leq \mathbf{b} \\ & \mathbf{x} \geq \mathbf{0}, \quad \mathbf{y} \in \{0, 1\}^p \end{aligned} \]
donde \(\mathbf{y} \in \{0, 1\}^p\) son las variables binarias de decisión.
Diferencias con LP
| Aspecto | LP | MILP |
|---|---|---|
| Variables | Continuas | Continuas + enteras/binarias |
| Región factible | Poliedro convexo | No convexo (puntos discretos) |
| Complejidad | Polinomial (Simplex, punto interior) | NP-hard en general |
| Solución | Vértice del poliedro | Branch-and-bound / Branch-and-cut |
| Tiempo de solución | Milisegundos (miles de variables) | Segundos a horas (según instancia) |
En este proyecto utilizamos LP con variables continuas \(x_i \in [0,1]\) en lugar de MILP con variables binarias \(y_i \in \{0,1\}\). Esto se justifica porque Lending Club permite financiar fracciones de préstamos (participación parcial). La relajación continua resuelve órdenes de magnitud más rápido y permite explorar el espacio de políticas robustas con miles de candidatos (\(n \leq 80{,}000\)).
21.2.3 Optimización Robusta
La optimización clásica (LP, MILP) asume que los parámetros del problema — costos, coeficientes, límites — son conocidos con certeza. En la práctica, los parámetros son estimaciones con incertidumbre: la PD predicha por un modelo de ML no es un valor exacto, sino una estimación sujeta a error.
La optimización robusta aborda esta realidad buscando soluciones que sean factibles y de buen desempeño para todos los valores posibles de los parámetros inciertos dentro de un conjunto de incertidumbre predefinido.
Formulación General
Sea \(\mathcal{U}\) un conjunto de incertidumbre que contiene los posibles valores del parámetro incierto \(\mathbf{d}\). La formulación robusta del LP es:
\[ \begin{aligned} \max_{\mathbf{x}} \quad & \min_{\mathbf{d} \in \mathcal{U}} \; \mathbf{c}(\mathbf{d})^\top \mathbf{x} \\ \text{s.a.} \quad & A(\mathbf{d})\mathbf{x} \leq \mathbf{b}(\mathbf{d}), \quad \forall \mathbf{d} \in \mathcal{U} \\ & \mathbf{x} \geq \mathbf{0} \end{aligned} \]
La clave es el operador \(\min_{\mathbf{d} \in \mathcal{U}}\): el optimizador busca la mejor decisión asumiendo que la naturaleza jugará en su contra, eligiendo la realización más adversa de la incertidumbre dentro de \(\mathcal{U}\). Es un juego minimax.
El Framework de Bertsimas y Sim
El enfoque seminal de Bertsimas & Sim (2004) introduce un parámetro \(\Gamma\) (Gamma) que controla el grado de conservadurismo de la solución robusta. La intuición es que, en la práctica, es improbable que todos los parámetros inciertos alcancen simultáneamente su peor caso.
Considérese una restricción nominal:
\[ \sum_{j=1}^{n} \bar{a}_j x_j \leq b \]
donde \(\bar{a}_j\) es el valor nominal del coeficiente \(a_j\) y su valor real puede variar en el intervalo \([\bar{a}_j - \hat{a}_j, \; \bar{a}_j + \hat{a}_j]\) con \(\hat{a}_j\) la semi-amplitud de incertidumbre.
El parámetro \(\Gamma \in [0, n]\) limita el número de coeficientes que pueden desviarse simultáneamente de su valor nominal. La restricción robusta de Bertsimas–Sim se escribe:
\[ \sum_{j=1}^{n} \bar{a}_j x_j + \max_{\substack{S \subseteq \{1,\ldots,n\} \\ |S| \leq \Gamma}} \sum_{j \in S} \hat{a}_j |x_j| \leq b \]
donde el segundo término representa el peor caso de que a lo sumo \(\Gamma\) coeficientes se desvíen al máximo.
- \(\Gamma = 0\): Solución nominal (sin protección contra incertidumbre). Equivalente a ignorar la incertidumbre.
- \(\Gamma = n\): Protección total (todos los parámetros en su peor caso simultáneamente). Máximamente conservador.
- \(0 < \Gamma < n\): Protección parcial. Bertsimas y Sim demuestran que la probabilidad de violación de la restricción decrece exponencialmente con \(\Gamma\), lo que permite calibrar el nivel de conservadurismo de forma precisa.
En este proyecto, \(\Gamma\) se controla mediante el parámetro gamma en las políticas de incertidumbre (blended_uncertainty, tail_blended_uncertainty, etc.), que interpola entre la PD puntual y el límite superior conformal.
La gran ventaja de este framework es que la formulación robusta resultante se resuelve como un LP (no requiere solvers de optimización robusta especializados), con apenas \(n\) variables y \(n\) restricciones adicionales respecto al LP nominal (Bertsimas & Sim, 2004).
21.2.4 Conjuntos de Incertidumbre de Caja (Box Uncertainty Sets)
Un conjunto de incertidumbre de caja es la forma más simple de representar incertidumbre: para cada parámetro incierto definimos un valor mínimo y un valor máximo aceptables, y el optimizador asume que la realidad podría caer en cualquier punto dentro de ese rango.
La forma más útil de entenderlo en este proyecto no es con geometría abstracta, sino con un ejemplo de negocio:
- si un préstamo tiene PD puntual de
0.12, - pero el módulo conformal dice que su rango plausible es
[0.08, 0.19], - entonces el optimizador no trabaja con un único número fijo, sino con la idea de que ese préstamo podría comportarse como un caso moderado o como uno bastante más riesgoso.
Cuando esto se hace para todos los préstamos elegibles, el portafolio deja de optimizar contra una foto puntual y empieza a optimizar contra una banda de riesgo plausible.
Conexión con Predicción Conformal
La innovación central de este proyecto es que los conjuntos de incertidumbre de caja se construyen directamente a partir de los intervalos de predicción conformal. Es decir, los límites inferior y superior no salen de una heurística arbitraria, sino de la misma capa que ya cuantificó incertidumbre en la PD.
En Lending Club, esto significa que dos préstamos con PD puntual parecida pueden entrar al optimizador con cajas muy distintas:
- uno puede tener un rango estrecho y, por tanto, una decisión relativamente confiable;
- otro puede tener un rango ancho, lo que obliga al optimizador a tratarlo con más cautela.
Esto conecta dos campos que históricamente han operado por separado:
| Componente | Campo de origen | Aporte al pipeline |
|---|---|---|
| Intervalos \([\text{PD}^{\text{low}}, \text{PD}^{\text{high}}]\) | Predicción conformal (ML/estadística) | Garantía de cobertura finita sin supuestos distribucionales |
| Conjunto \(\mathcal{U}_{\text{box}}\) | Optimización robusta (OR) | Protección contra peor caso dentro del conjunto |
| Pipeline completo | Predict-then-Optimize | Decisiones óptimas con incertidumbre cuantificada y garantizada |
En src/optimization/robust_opt.py, la función build_box_uncertainty_set() toma los vectores pd_low y pd_high del predictor conformal y arma los rangos que luego consume el optimizador. El modelo de portafolio en src/optimization/portfolio_model.py utiliza diferentes políticas de incertidumbre que deciden cuánto peso dar a la PD puntual y cuánto peso dar al límite superior conformal.
Johnstone & Cox (2021) formalizan esta conexión y muestran por qué tiene sentido pasar de intervalos conformales a conjuntos de incertidumbre utilizables por optimización robusta.
21.2.5 Precio de la Robustez (Price of Robustness)
Toda protección contra incertidumbre tiene un costo. El Precio de la Robustez (PoR) cuantifica cuánto retorno se sacrifica al adoptar una solución robusta en lugar de la solución nominal que ignora la incertidumbre.
En lenguaje simple, el PoR responde a esta pregunta: ¿cuánto dinero dejo sobre la mesa por volverme más prudente?
Ejemplo con el proyecto:
- una política nominal puede prometer un retorno más alto porque cree ciegamente en la PD puntual;
- una política robusta acepta un retorno algo menor para no sobreexponerse a préstamos cuyo riesgo real podría estar más cerca de
PD_high; - la diferencia relativa entre ambas es el Precio de la Robustez.
Si el sacrificio es pequeño, la prudencia sale barata. Si el sacrificio es demasiado grande, probablemente estamos siendo más conservadores de lo que el negocio puede justificar.
Interpretación Práctica
| PoR | Interpretación |
|---|---|
| 0% | Sin protección (solución nominal) |
| 1–5% | Protección moderada con sacrificio mínimo |
| 5–15% | Protección significativa; típica en portafolios regulados |
| > 15% | Excesivamente conservador; puede indicar intervalos demasiado anchos |
En la configuración del proyecto (configs/optimization.yaml), el parámetro max_price_of_robustness_pct establece un umbral de -15%. Si una política robusta sacrifica más del 15% de retorno respecto al equivalente no robusto, se activa la política de fallback (nonrobust_equivalent). Este mecanismo evita que intervalos conformales excesivamente conservadores produzcan portafolios poco defendibles desde negocio.
El campo congelado price_of_robustness=-10.56% queda retirado porque la baseline histórica etiquetada como no robusta heredaba la restricción pd_high. A40 reconstruye una baseline point-PD con los mismos 276,869 candidatos, presupuesto, concentración, tau=0.1715, LGD y solver. CRPTO cede 5.875% de retorno realizado, reduce default/V ponderado en 8.305 puntos porcentuales y baja el umbral Markov exacto en 43.55 puntos. Esta comparación no cambia el certificado seleccionado; aclara su costo económico contra un control semánticamente equivalente.
La frontera de Pareto entre retorno y robustez se explora en el script scripts/optimize_portfolio_tradeoff.py, que genera el tradeoff curve variando el parámetro \(\gamma\) y registrando el PoR resultante.
21.2.6 Medidas de Riesgo de Cola: CVaR y OCE
El precio de la robustez resume el costo promedio de protegerse, pero no dice nada sobre la cola de la distribución de pérdidas del portafolio. Para auditar ese extremo, el proyecto reporta dos medidas de riesgo coherentes ampliamente usadas en finanzas, siempre como diagnóstico post-hoc del funded set congelado (no como objetivo optimizado; ver Tabla A12 del supplement).
Conditional Value-at-Risk (CVaR). Introducida por Rockafellar & Uryasev (2000), la CVaR al nivel \(\beta\) es la pérdida esperada condicional a estar en el peor \((1-\beta)\) de los escenarios. Su forma variacional, clave para la tratabilidad, es:
\[ \text{CVaR}_\beta(L) = \min_{\eta \in \mathbb{R}}\;\Big\{\,\eta + \tfrac{1}{1-\beta}\,\mathbb{E}\big[(L-\eta)^+\big]\Big\} \tag{21.1}\]
A diferencia del VaR, la CVaR es coherente (en particular subaditiva) y convexa en la asignación, de modo que minimizar CVaR sobre el portafolio sigue siendo un LP. En CRPTO la usamos para verificar que el funded set promovido no esconde una cola de pérdidas desproporcionada frente a las demás políticas de la región robusta.
Optimized Certainty Equivalent (OCE). Propuesto por Ben-Tal & Teboulle (2007), el OCE generaliza la utilidad esperada: para una función de desutilidad \(u(\cdot)\) convexa, no decreciente y normalizada,
\[ \text{OCE}_u(L) = \min_{\eta \in \mathbb{R}}\;\Big\{\,\eta + \mathbb{E}\big[u(L-\eta)\big]\Big\} \tag{21.2}\]
La CVaR es un caso particular del OCE con desutilidad lineal a trozos \(u(t)=\tfrac{1}{1-\beta}t^+\). El OCE entrega así una familia paramétrica de medidas coherentes que permite estresar el funded set bajo distintas aversiones a la cola sin reentrenar nada.
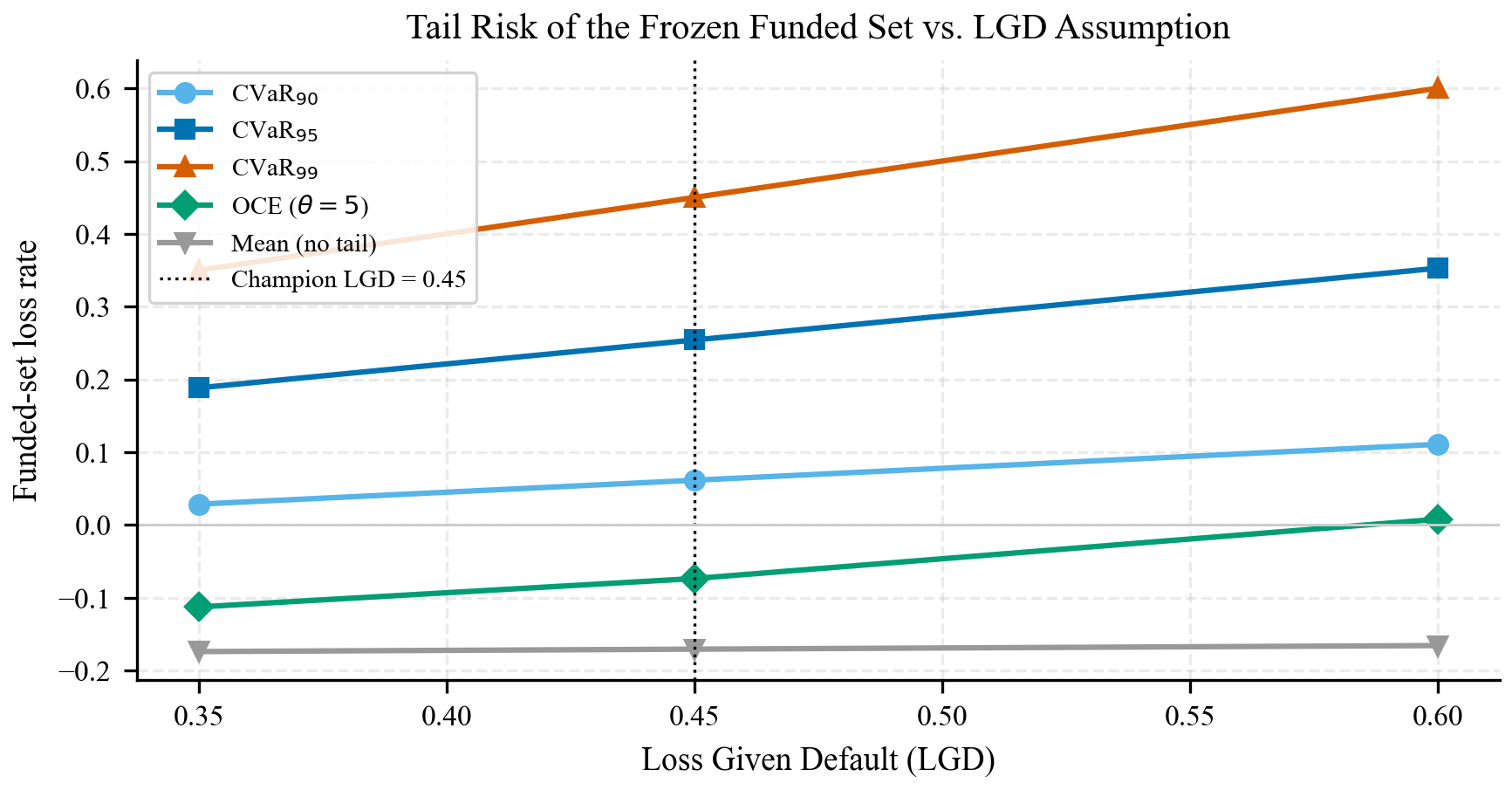
Dos políticas con el mismo retorno esperado pueden tener colas de pérdida muy distintas. CVaR y OCE hacen visible esa diferencia y conectan el lenguaje conformal (cobertura del peor caso por préstamo, vía \(u_i(\alpha)\)) con el lenguaje de riesgo financiero (pérdida esperada en la cola del portafolio). En el proyecto son diagnósticos que refuerzan la decisión congelada; convertir OCE/CVaR en el objetivo optimizado es trabajo futuro explícito.
21.2.7 Smart Predict, then Optimize (SPO+)
Esta sección existe porque el pipeline del libro no se detiene en “predecir bien”: necesita que la predicción ayude a decidir mejor. Antes de entrar a la pérdida SPO+, conviene fijar esa intuición en lenguaje de negocio: un error pequeño en MSE puede ser irrelevante, mientras que un error que cruce un umbral de aprobación o cambie una asignación de capital sí puede destruir valor.
El Problema del Two-Stage Pipeline
El enfoque clásico en ML operacional sigue un pipeline de dos etapas desacopladas:
- Predict: Entrenar un modelo ML para minimizar error de predicción (MSE, log-loss, etc.).
- Optimize: Usar las predicciones como entrada para un modelo de optimización que toma decisiones.
El problema fundamental es que minimizar el error de predicción no es equivalente a maximizar la calidad de las decisiones. Un modelo con menor MSE no necesariamente produce mejores decisiones de portafolio, porque las predicciones que más importan para la decisión óptima no son necesariamente las que más contribuyen al MSE agregado.
Supongamos dos préstamos con PD real de 0.09 y 0.11, y un umbral de aprobación en PD = 0.10.
- Modelo A (MSE menor): predice 0.085 y 0.115. Buen MSE, decisión correcta (rechaza el segundo).
- Modelo B (MSE mayor): predice 0.12 y 0.08. Peor MSE, pero decisión incorrecta (aprueba el segundo, rechaza el primero).
La pérdida de predicción no captura que el error de B cruza el umbral de decisión, generando una mala asignación de capital.
La Pérdida SPO+
Elmachtoub & Grigas (2022) proponen la pérdida SPO+ (Smart Predict, then Optimize), que entrena el modelo de predicción directamente para optimizar la calidad de las decisiones downstream. La idea central es reemplazar la pérdida de predicción por una pérdida de regret (arrepentimiento decisional).
Sea \(\mathbf{c}\) el vector de costos verdadero y \(\hat{\mathbf{c}}\) la predicción. Sea \(\mathbf{x}^*(\mathbf{c})\) la decisión óptima bajo costos verdaderos y \(\mathbf{x}^*(\hat{\mathbf{c}})\) la decisión tomada con la predicción. El regret se define como:
\[ \text{Regret}(\hat{\mathbf{c}}, \mathbf{c}) = \mathbf{c}^\top \mathbf{x}^*(\hat{\mathbf{c}}) - \mathbf{c}^\top \mathbf{x}^*(\mathbf{c}) \]
Es decir, la diferencia de costo real entre la decisión tomada con la predicción y la decisión que se habría tomado con información perfecta. El regret es siempre \(\geq 0\).
La pérdida SPO+ es una cota superior convexa del regret, diseñada para ser diferenciable y tratable computacionalmente:
\[ \ell_{\text{SPO+}}(\hat{\mathbf{c}}, \mathbf{c}) = -\min_{\mathbf{x} \in \mathcal{X}} (2\hat{\mathbf{c}} - \mathbf{c})^\top \mathbf{x} + 2\hat{\mathbf{c}}^\top \mathbf{x}^*(\mathbf{c}) - \mathbf{c}^\top \mathbf{x}^*(\mathbf{c}) \]
donde \(\mathcal{X}\) es el conjunto factible del problema de optimización.
Propiedades de SPO+
- Consistencia Fisher: Minimizar SPO+ en expectativa implica minimizar el regret verdadero.
- Convexidad: \(\ell_{\text{SPO+}}\) es convexa en \(\hat{\mathbf{c}}\), lo que permite optimización con gradiente.
- Subgradiente simple: El subgradiente respecto a \(\hat{\mathbf{c}}\) es \(2(\mathbf{x}^*_{\text{SPO}} - \mathbf{x}^*(\mathbf{c}))\), donde \(\mathbf{x}^*_{\text{SPO}}\) es la solución del LP con costos \(2\hat{\mathbf{c}} - \mathbf{c}\).
- Generalidad: Funciona para cualquier problema de optimización lineal (LP, shortest path, knapsack, etc.).
Comparación: MSE vs SPO+
| Aspecto | MSE (Two-Stage) | SPO+ (Decision-Focused) |
|---|---|---|
| Objetivo | Minimizar error de predicción | Minimizar regret decisional |
| Gradiente | \(2(\hat{\mathbf{c}} - \mathbf{c})\) | \(2(\mathbf{x}^*_{\text{SPO}} - \mathbf{x}^*(\mathbf{c}))\) |
| Sensibilidad a la decisión | Ninguna | Total: penaliza errores que cambian la decisión óptima |
| Costo computacional | Bajo (sin resolver LP) | Alto (requiere resolver LP en cada forward pass) |
| Garantía teórica | Consistencia estadística para predicción | Consistencia Fisher para decisión óptima |
Aplicación en Riesgo Crediticio
En este proyecto, SPO+ se aplica de la siguiente manera:
- Los costos \(\mathbf{c}\) son las PD calibradas de cada préstamo (costos continuos, no binarios).
- El problema de optimización es el LP de asignación de portafolio.
- Una red neuronal (MLP) se entrena con SPO+ loss para predecir PDs que minimicen el regret de la asignación de portafolio.
- El resultado se compara contra el pipeline two-stage (CatBoost PD → LP) para cuantificar la reducción de regret.
El pipeline SPO+ v2 del proyecto logra una reducción de regret del 49.09% respecto al two-stage baseline en el artefacto local A19/Figura 15 (0.425896 a 0.216837, Wilcoxon p = 1.39e-164). El cierre curado PyEPO 1.3.7 reporta una lectura compatible de 48.51% bajo un protocolo pareado separado (0.358073 a 0.184366, Wilcoxon p = 3.80e-163). Esto demuestra que optimizar directamente la calidad de la decisión crediticia produce portafolios sustancialmente mejores que optimizar la precisión de la predicción y luego usar esas predicciones como entrada a un optimizador.
Un aspecto crítico de implementación es que SPO+ requiere costos continuos, no binarios. Usar labels binarios de default (0/1) produce un paisaje de pérdida plano donde el gradiente de SPO+ es casi cero. Por esto, el proyecto utiliza las PDs calibradas como costos del LP, lo que produce un paisaje de gradientes informativo.
21.2.8 El Solver HiGHS
La resolución de los problemas LP y MILP formulados en este proyecto se realiza mediante HiGHS (High-performance Software for Linear Optimization), un solver de código abierto desarrollado en la Universidad de Edimburgo.
Justificación de la elección
| Criterio | HiGHS | Gurobi | CPLEX |
|---|---|---|---|
| Licencia | MIT (código abierto) | Comercial ($$$) | Comercial ($$$) |
| Rendimiento LP | Estado del arte | Estado del arte | Estado del arte |
| Rendimiento MILP | Competitivo | Superior | Superior |
| Reproducibilidad | Total (sin licencia) | Limitada (requiere licencia) | Limitada (requiere licencia) |
| Integración Python | highspy, Pyomo, CVXPY |
gurobipy, Pyomo |
docplex, Pyomo |
| Uso académico | Sin restricciones | Licencia académica gratuita | Licencia académica gratuita |
Se eligió HiGHS por tres razones: (1) reproducibilidad total — cualquier persona puede ejecutar el pipeline sin obtener una licencia comercial; (2) rendimiento suficiente para las instancias del proyecto (hasta 80,000 variables, resuelto en milisegundos a segundos); y (3) integración nativa con Pyomo, el framework de modelado algebraico utilizado en src/optimization/portfolio_model.py. Para instancias de escala industrial donde MILP con cientos de miles de variables binarias sea necesario, Gurobi o CPLEX ofrecerían tiempos de solución menores.
En el proyecto, HiGHS se invoca a través de Pyomo con la configuración definida en configs/optimization.yaml: tiempo límite de 300 segundos y 16 threads de paralelismo.
21.2.9 Pipeline Integrado: Predict-then-Optimize con Incertidumbre Conformal
El pipeline completo del proyecto integra todos los conceptos presentados en esta sección en una cadena coherente:
CatBoost PD Calibración Mondrian [PD_low, PD_high] U_box LP Robusto x*
Este pipeline tiene tres propiedades que lo distinguen del enfoque estándar en credit risk analytics:
- Garantía de cobertura: Los intervalos conformales tienen cobertura \(\geq 1 - \alpha\) en muestra finita, sin supuestos distribucionales.
- Protección contra incertidumbre: La solución robusta es factible para cualquier realización de la PD dentro del conjunto de incertidumbre.
- Costo controlado: El Precio de la Robustez cuantifica explícitamente el tradeoff retorno-resiliencia, permitiendo decisiones informadas.
El enfoque SPO+ complementa este pipeline: donde el pipeline clásico (predict-then-optimize) toma las predicciones como dadas y optimiza sobre ellas, SPO+ cierra el ciclo entrenando el predictor para que produzca las predicciones que generen las mejores decisiones, no las mejores predicciones.
21.2.10 Referencias Clave
Las referencias fundamentales para los conceptos de esta sección son:
- Bertsimas & Sim (2004) — The Price of Robustness: Introduce el framework de optimización robusta con el parámetro \(\Gamma\) que controla el conservadurismo, demostrando que la protección contra incertidumbre tiene un costo predecible y controlable. Formulación tratable (LP) para problemas robustos.
- Elmachtoub & Grigas (2022) — Smart Predict, then Optimize: Propone la pérdida SPO+ para entrenamiento decision-focused, demostrando consistencia Fisher y superioridad empírica sobre el pipeline two-stage desacoplado. Publicado en Management Science.
- Johnstone & Cox (2021) — Conformal Uncertainty Sets for Robust Optimization: Formaliza la conexión entre intervalos conformales y conjuntos de incertidumbre para optimización robusta, proporcionando la base teórica para el uso de predicción conformal en el contexto de OR.