7 Resultados
Los resultados del CRPTO deben leerse como una prueba de viabilidad del marco, no como un torneo aislado de AUC. La evidencia relevante está en la interacción entre incertidumbre y decisión.
Nota de gobernanza (actualizada 2026-07-09): este capítulo conserva la cadena upstream congelada (rebaseline ijds-rebaseline-2026-06-07, retorno $170,464.54) como floor declarado. El body claim IJDS es el punto pool93 ($184,832.48, V=0.035350, Γ_CP=0.162616, Γ_res=0.073584, umbral Markov 0.345084, 8/8) sobre los mismos intervalos; ver A35–A40 y tests/test_pool93_body_claim_sync.py.
7.0.1 Base predictiva e incertidumbre
El pipeline base sobre el champion monotónico confirmatorio sigue aportando la base regulatoria y probabilística del sistema:
| Indicador | Valor |
|---|---|
| AUC OOT | 0.7139 |
| ECE | 0.0070 |
| Cobertura conformal 90% | 92.97% |
| Cobertura conformal 95% | 96.64% |
| Ancho medio 90% | 0.7842 |
La lectura correcta es doble. Primero, el canónico monotónico ya es una base fuerte para operación, gobernanza e IFRS9. Segundo, esa base todavía no basta para el claim más exigente del paper: convertir el teorema en una afirmación exacta sobre el funded set a alpha = 0.01.
7.0.2 Calidad estadística de la calibración
El paper documenta formalmente la calibración del modelo base mediante los tests estadísticos de MAPIE. Los resultados confirman que el modelo PD supera los tests de calibración antes de entrar al layer conformal:
| Test | Calibrado (p-value) | Sin calibrar (p-value) | Mejora relativa |
|---|---|---|---|
| Kolmogorov-Smirnov | \(1.3 \times 10^{-9}\) | \(4.8 \times 10^{-12}\) | ~3,800× |
| Kuiper | \(2.5 \times 10^{-9}\) | \(1.5 \times 10^{-13}\) | ~60,000× |
| Spiegelhalter z | \(5.9 \times 10^{-15}\) | \(3.7 \times 10^{-14}\) | ~6× |
A \(n = 276{,}869\), cualquier desviación microscópica de calibración perfecta produce un rechazo formal. El indicador operativamente relevante es el ECE = 0.0070 (menos de 1 punto porcentual de error medio de calibración), que confirma calibración práctica excelente. Los p-values de la tabla deben leerse en clave relativa: la calibración Venn-Abers mejora la fidelidad probabilística entre 6× y 60,000× según el test, aunque ningún modelo logra calibración perfecta a esta escala muestral.
Un conjunto de incertidumbre conformal tiene garantía de cobertura marginal incluso sobre un modelo mal calibrado, pero producirá intervalos sistemáticamente más anchos. El cierre final del proyecto refuerza una lección metodológica importante: la mejora decisiva no vino de “más AUC”, sino de una cadena mejor compuesta de score monotónico, calibración Venn-Abers, conformal reabierto y policy bound-aware. Esa cadena reduce prima inútil de incertidumbre sin sacrificar trazabilidad.
El artefacto data/processed/statistical_calibration_tests.json guarda los p-values y el artefacto data/processed/calibration_cumulative_diffs.parquet las diferencias acumuladas para replicación o extensión.
Los tests de backtesting secuencial de Kupiec y Christoffersen se conservan como funciones de investigación, pero ya no forman parte del artefacto oficial de promoción. En esta muestra OOT de 276,869 préstamos, la cobertura empírica (92.97% al 90%, 96.64% al 95%) supera el target nominal, por lo que un test de igualdad exacta convierte sobre-cobertura prudente en ruido editorial. El rebaseline IJDS promueve una lectura más limpia: overall_pass = true, gate_overall_pass = true y strict_overall_pass = true sobre 9/9 checks materiales de cobertura, cobertura por grupo, ancho, alertas y Winkler.
7.0.3 Baselines de incertidumbre
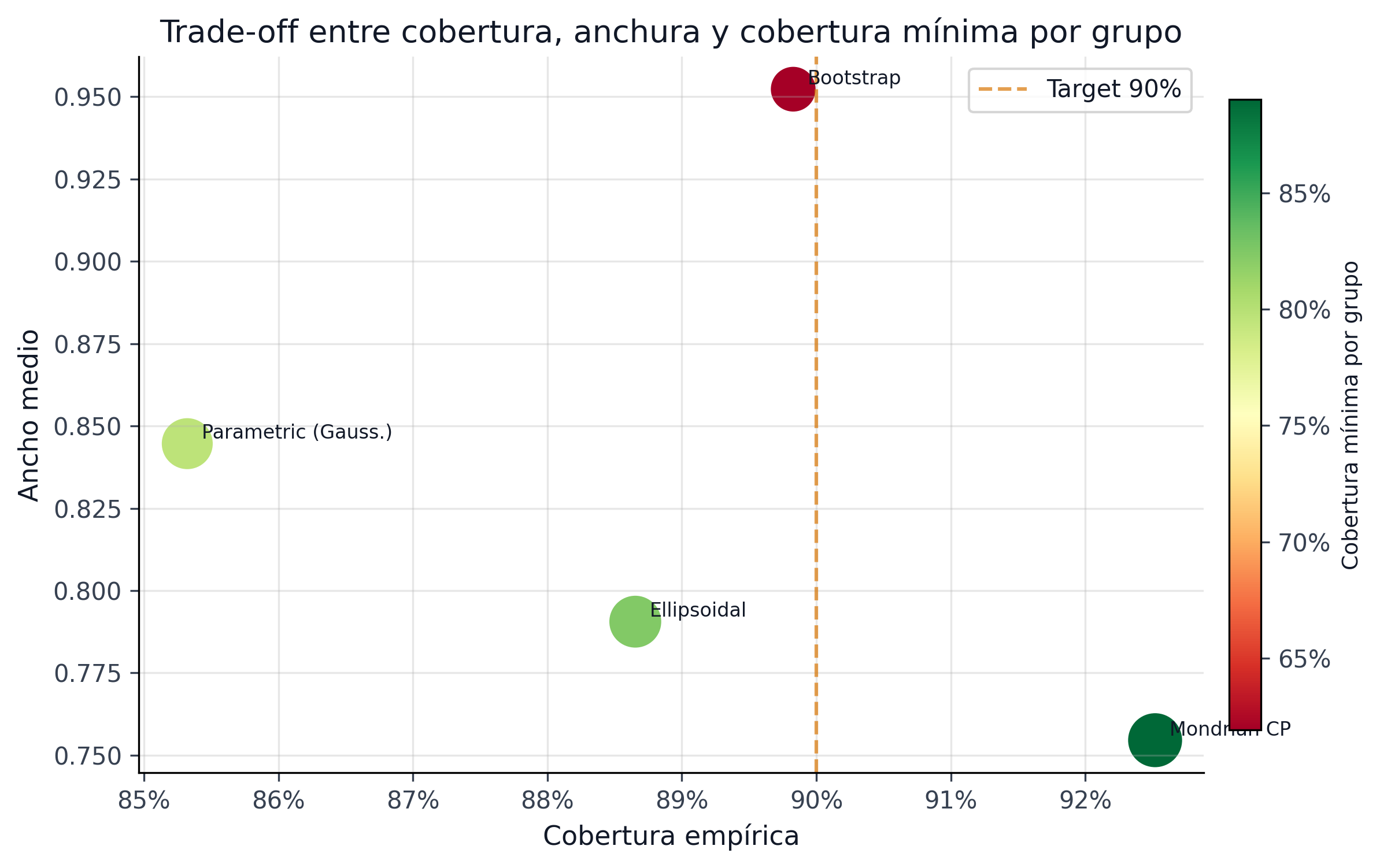
Frente al bootstrap y otros métodos clásicos, la banda conformal entrega un mejor equilibrio:
| Método | Tipo de conjunto | Cobertura | Ancho medio | Min group coverage | Garantía formal |
|---|---|---|---|---|---|
Winner conformal (score_decile_mondrian) |
Box (cota superior por loan) | 92.97% | 0.7842 | 91.90% | Sí (marginal, distribution-free) |
| Bootstrap percentil | Box (percentil empírico) | 89.83% | 0.9523 | 61.93% | No (asintótica) |
| BMA (Bayesian Model Averaging) | Elipsoidal (posteriors) | ~90% | Depende del prior | No evaluado | Condicional al prior |
| Bertsimas-Sim (\(\Gamma\) fijo) | Presupuesto de desviaciones | Por diseño | Depende de \(\Gamma\) | No evaluado | Sí (worst-case) |
La ventaja competitiva del enfoque conformal no es solo cobertura — es la combinación de cobertura verificable, anchura controlable vía \(\alpha\) y garantía distribution-free sin supuestos sobre el DGP. El bootstrap requiere re-entrenamiento múltiple sin garantías finitas; BMA requiere especificación correcta del espacio de modelos; Bertsimas-Sim deja abierta la calibración de \(\Gamma\). CRPTO hereda el \(\Gamma\) directamente de la capa conformal (def-gamma-cp).
La tabla anterior resume la lectura paper-facing. La siguiente tabla baja un nivel y muestra el comparador regenerado desde artefactos, donde todos los métodos se evalúan bajo el mismo protocolo de baseline de incertidumbre. La cifra conformal de esta tabla no reemplaza las métricas oficiales del champion (92.97%, 0.7842, 91.90%), sino que documenta el ejercicio comparativo que explica por qué el conjunto conformal es el único candidato que combina cobertura, anchura y préstamos operativamente fundables.
El corte por grado es todavía más revelador. Los métodos alternativos pueden parecer razonables en cobertura global, pero colapsan justo donde un comité de riesgo preguntaría primero: el peor grado o segmento.
El resultado fuerte no es que conformal sea el método con mayor cobertura global en cualquier protocolo. El resultado fuerte es que solo el baseline conformal mantiene una cobertura mínima por grado cerca del target y además deja préstamos fundables bajo el criterio operativo pd_high < 0.10. Bootstrap logra una cobertura global cercana al 90%, pero su peor grado cae a ~63% y no deja candidatos fundables bajo ese gate; el paramétrico y el elipsoidal tampoco cierran la combinación de cobertura por segmento y utilidad de decisión. Esa es exactamente la razón por la que el paper no vende “intervalos por intervalos”, sino intervalos que sobreviven al paso de incertidumbre a decisión.
7.0.4 Del canónico al cierre económico unificado
La progresión más informativa del paper no es la tabla de AUC, sino la secuencia completa de cierre del bound. El artefacto final_project_summary.parquet conserva ese camino histórico y final_project_promotion.json refresca los roles editoriales del rebaseline IJDS:
La secuencia deja una historia muy clara:
- el canónico monotónico sigue siendo una base productiva fuerte, pero falla
alpha = 0.01; - el conformal-only mejora el bound y elimina la violación observada, pero todavía no cierra
alpha = 0.01; 5kdemuestra existencia de una primera policy alpha01-safe;25kconfirma que la región no era un artefacto de un subset pequeño;276kmuestra la señal decisiva: el OOT completo admite una región robusta completa y no solo un punto milagroso.
El aprendizaje metodológico más importante aparece justamente aquí: el cuello de botella de alpha = 0.01 no era “más search conformal”, sino la composición del funded set. La reapertura conformal fue necesaria, pero el salto decisivo vino cuando la búsqueda de portfolio pasó a estar ordenada por métricas exactas del bound.
7.0.5 Región robusta completa en 276,869 préstamos OOT
Este resultado cambia la narrativa del paper de forma importante. Ya no estamos defendiendo “una configuración encontró un pase en alpha=0.01”. Estamos defendiendo algo más fuerte: la mini-grid final entera es robusta, y la decisión final pasa a ser una decisión editorial/metodológica dentro de una región ya validada.
Una crítica natural a cualquier procedimiento de búsqueda intensiva es la sospecha de post-selección: “buscaste hasta encontrar una policy que pasa el bound; eso es overfitting al test set OOT”. La defensa empírica directa es que 45 de 45 policies de la mini-grid pasan exacto el bound α = 0.01 sobre el OOT completo de 276,869 préstamos. No hay una policy ganadora aislada — hay una región completa de policies factibles, que cubre el rango risk_tolerance ∈ [0.155, 0.175] × gamma ∈ [0.45, 0.55] × uncertainty_aversion ∈ [0.0, 0.1]. La elección del economic champion dentro de esa región es una decisión editorial (qué retorno-tightness se prefiere), no una afirmación empírica frágil. La composición de ese funded set se descompone en Sección 17.1; la ablación de la capa conformal que la habilitó está en Sección 13.1; el heatmap de la región robusta entera vive como Figura 14 en Sección 12.1.
7.0.6 Champion económico y comparadores de la región robusta
El 276k deja tres puntos importantes:
- Champion económico:
0.175 / blended / 0.45 / aversion 0.10Maximiza retorno entre losalpha01 passers. - Comparator theorem-tight:
0.175 / blended / 0.55 / aversion 0.10MinimizaVy mejoragamma_cp; queda como comparador de tightness dentro de la misma región robusta. - Comparator balanceado:
0.170 / blended / 0.45 / aversion 0.10Casi iguala el retorno máximo con una postura ligeramente menos agresiva.
El artefacto del run 276k conserva al champion económico como selección interna del barrido, y el proyecto final hoy queda alineado con esa misma policy vía models/final_project_promotion.json y models/champion_portfolio_policy.json. Con esto se elimina la dualidad anterior entre selector económico del run y promoción editorial final.
La validación A/B bootstrap refuerza este cierre: la simulación retroactiva de la policy champion contra la policy nominal (sin incertidumbre) sobre el OOT completo confirma que la región robusta no depende de una sola partición de datos. Las 45 políticas de la región pasan el gate A/B (ab_pass_all = true) con diferencia de retorno consistente, lo que permite defender el champion ante comité sin depender de un resultado puntual.
El comparador theorem-tight sigue siendo metodológicamente valioso porque muestra que la región robusta admite una variante con tightness adicional: - alpha01_exact_pass = true - violation = 0 - V = 0.026875 - gamma_cp = 0.160299 - y retorno todavía fuerte ($166.3K)
Baseline point-PD emparejada (A40)
El campo congelado price_of_robustness=-10.56% no debe usarse: su baseline histórica heredaba pd_high. A40 resuelve un control point-PD con los mismos 276,869 candidatos, presupuesto, concentración, tau=0.1715, LGD y solver que la decisión seleccionada. El control realiza $196,369.14 y CRPTO $184,832.48: costo $11,536.66 (5.875%). A cambio, default/V ponderado baja de 0.118400 a 0.035350 y el umbral Markov exacto de 0.780579 a 0.345084. Esta es la comparación económica activa; no es evidencia causal ni universal.
El comparador theorem-tight (gamma=0.55) conserva su lectura válida en los ejes que sí fueron calculados sobre la policy robusta: baja \(\Gamma_{\text{CP}}\) a 0.160299 con un retorno realizado menor ($166,270). La frontera defendible es retorno–bound–\(\Gamma_{\text{CP}}\); los precios históricos relativos a la baseline retirada no se usan para ordenarla.
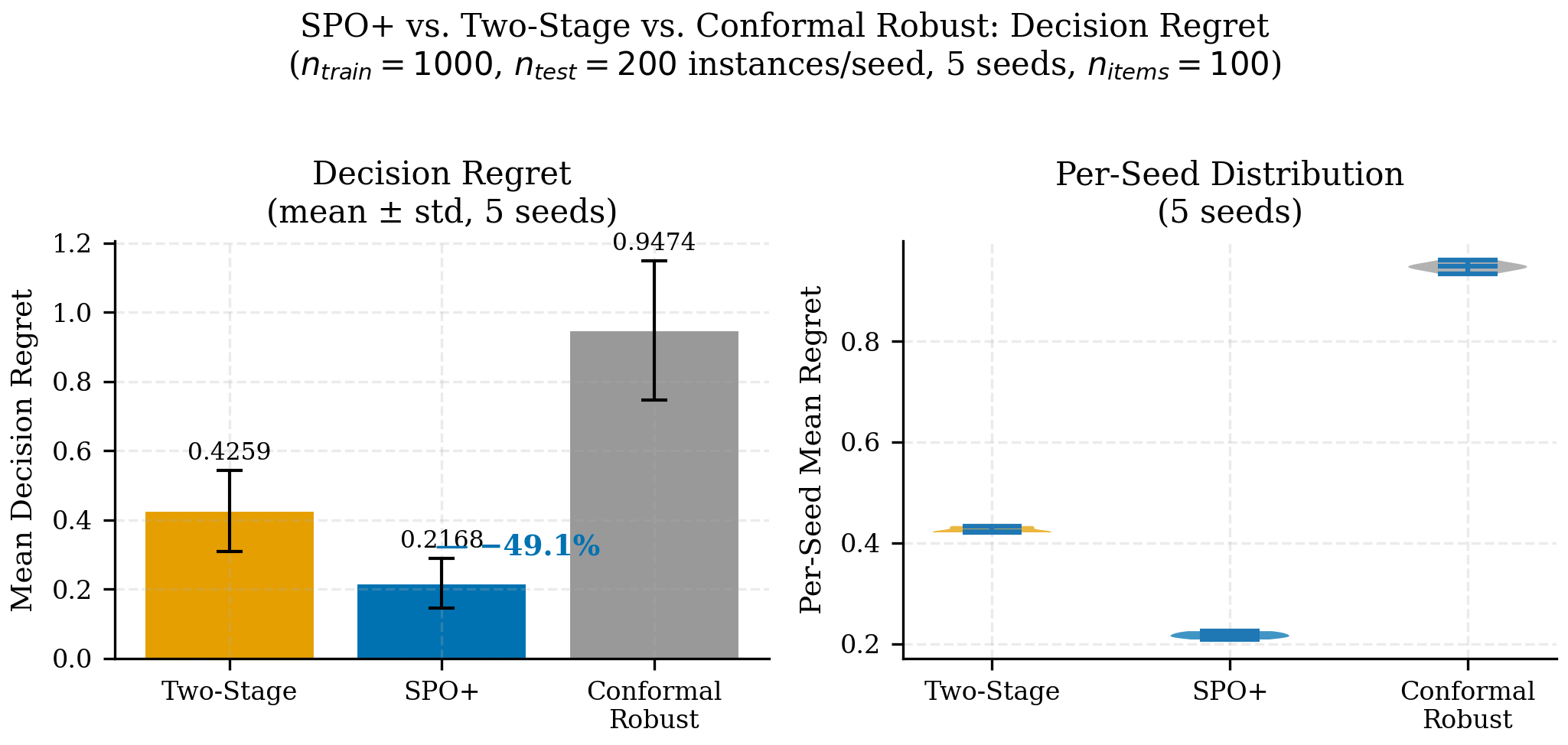
La Figura 7.3 no muestra que CRPTO “pierde” contra SPO+; muestra el trade-off diseñado: SPO+ optimiza regret directamente (49.09% de reducción en el artefacto local; 48.51% en el closeout PyEPO pareado 2026-05-28), mientras CRPTO optimiza robustez bajo incertidumbre auditable. El regret más alto de CRPTO es el precio de la auditabilidad — la policy es más conservadora porque protege contra realizaciones adversas con cobertura verificable (92.97%). Un regulador puede auditar la cobertura de CRPTO; no puede auditar si el regret de SPO+ se mantendrá bajo distributional shift.
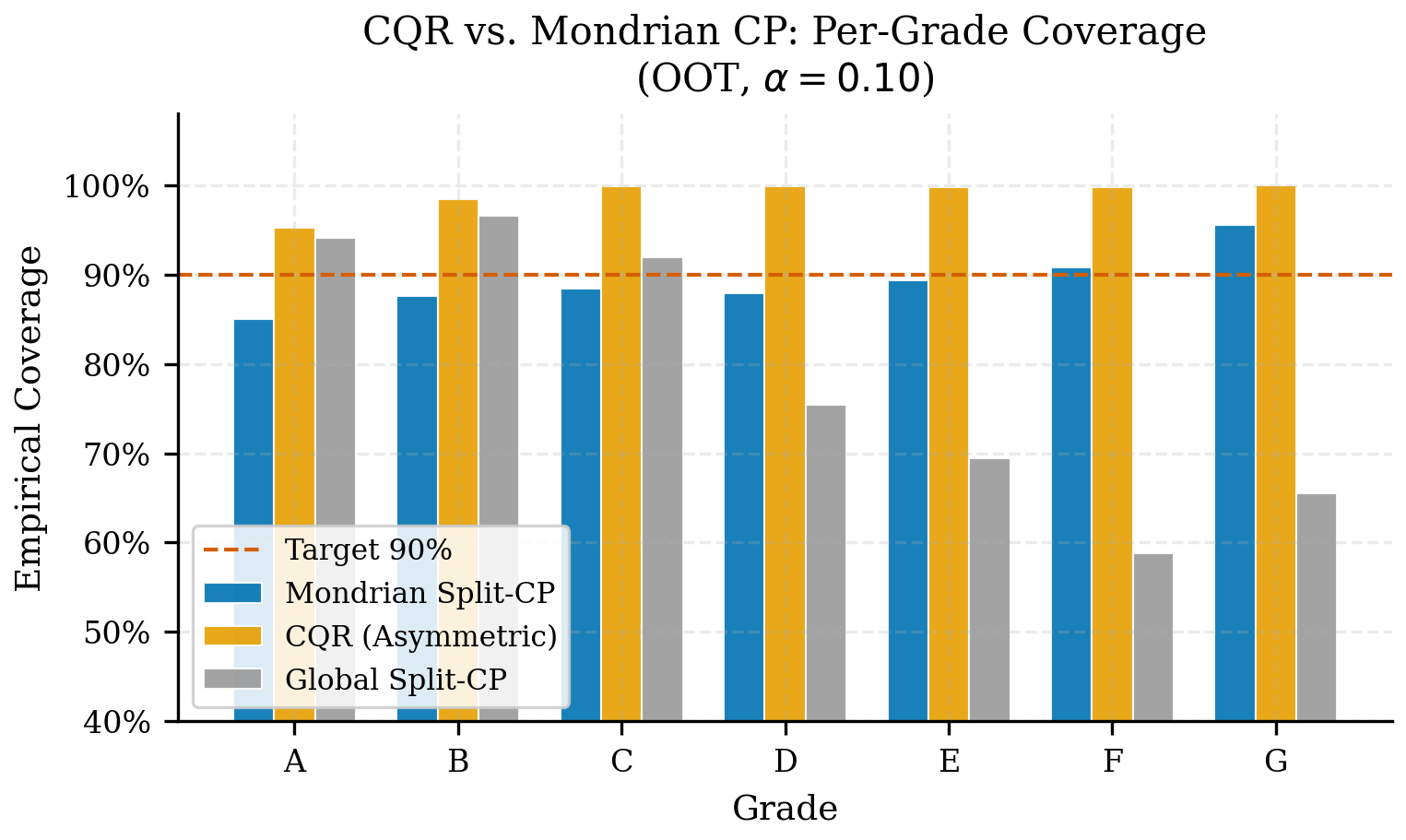
CQR como comparador, no reemplazo del winner
La Figura Figura 7.4 queda mejor interpretada con su tabla de soporte. CQR es valioso como comparador moderno porque aprende cuantiles condicionales, pero en este pipeline específico su versión evaluada termina siendo demasiado conservadora para la decisión de portafolio: cubre bastante, pero no produce préstamos elegibles bajo el gate pd_high < 0.10.
CQR no queda descartado como literatura ni como línea futura. Queda descartado como reemplazo inmediato del score_decile_mondrian oficial porque, bajo los artefactos actuales, su ganancia de cobertura viene con anchura extrema y cero préstamos elegibles. En un paper journal podría volver como extensión si el modelo de cuantiles se reentrena con objetivo de decisión o si se relaja el gate operativo, pero eso ya sería un nuevo experimento y no una promoción editorial del champion actual.
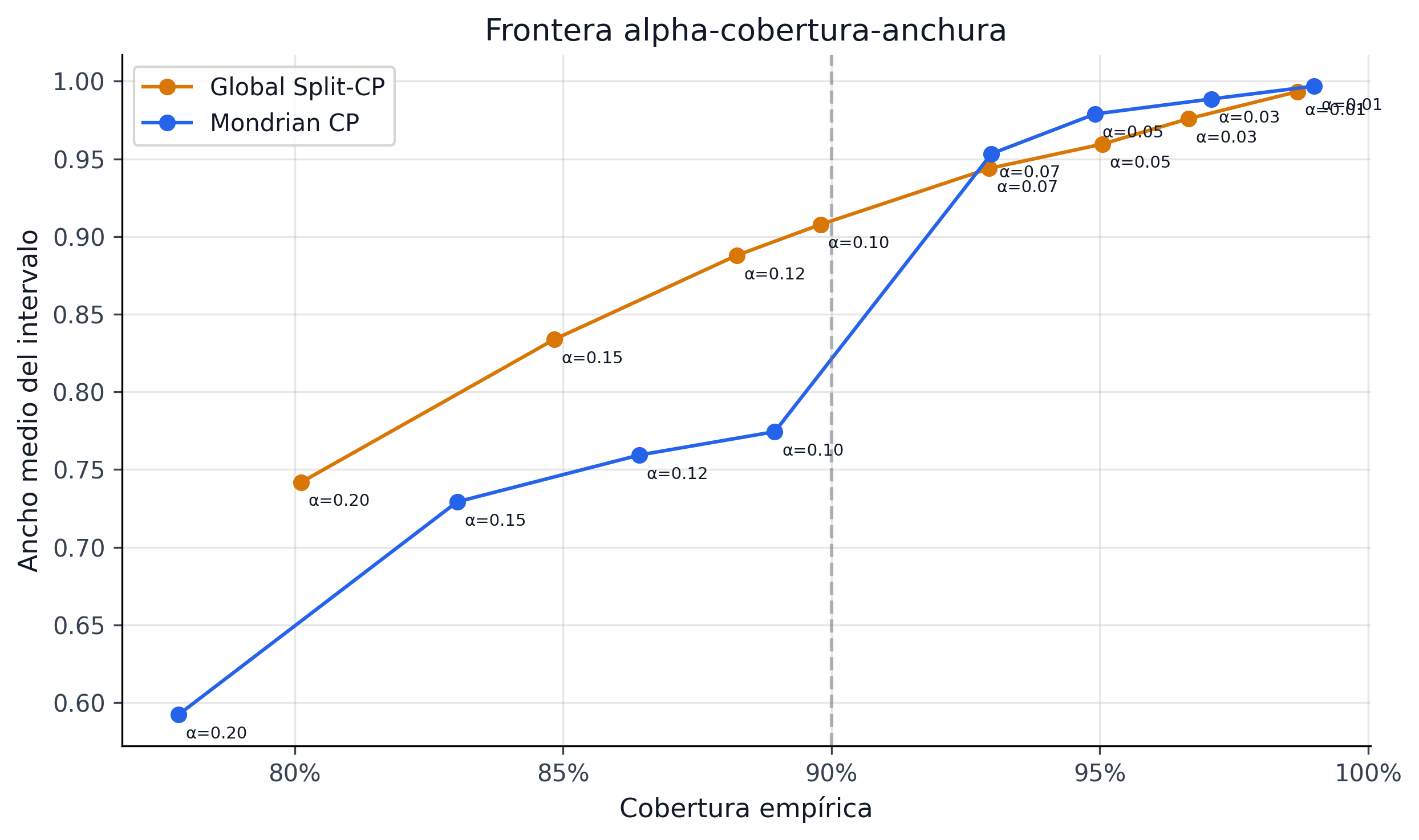
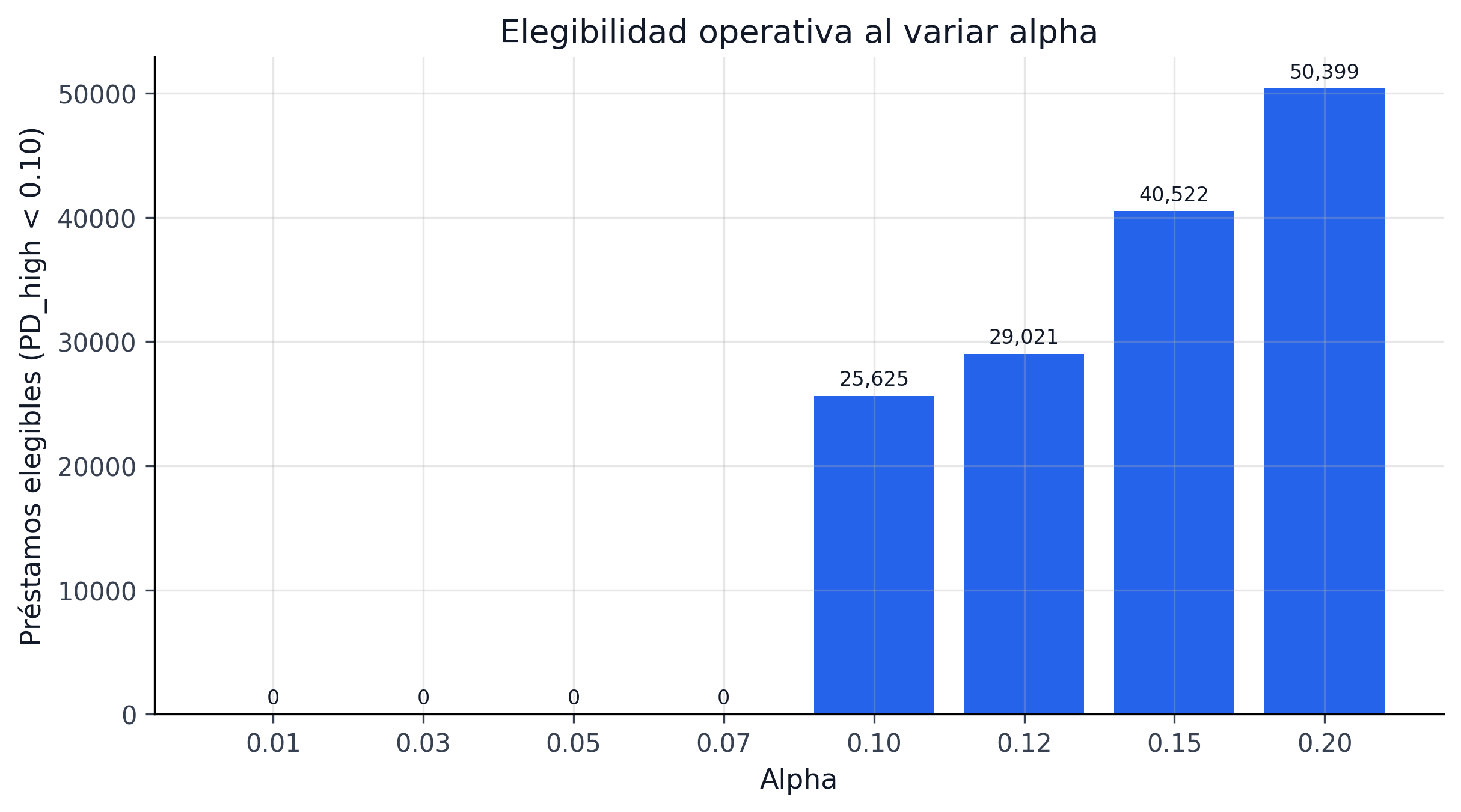
7.0.7 Frontera de alpha
El alpha sweep muestra que subir confianza ensancha rápidamente el conjunto y reduce la flexibilidad de decisión. Esa frontera es uno de los hallazgos más útiles del paper porque convierte un hiperparámetro estadístico en una palanca explícita de política económica.
Protocolo del barrido
El sweep evalúa la familia completa de cota superior \(u_i(\alpha) = \widehat{p}_i + q_{1-\alpha,g_i}\) para \(\alpha \in \{0.01, 0.03, 0.05, 0.10, 0.15, 0.20\}\) y cada \(\alpha\) se compone con la política blended_uncertainty con gamma = 0.45, sobre el OOT completo de 276,869 préstamos. Los pasos son los siguientes:
- Generar \(u_i(\alpha)\) para cada \(\alpha\) del grid usando los cuantiles de no conformidad por grupo Mondrian (winner:
score_decile_mondrian, ver Sección 13.1). - Resolver el LP robusto con esa cota superior,
risk_tolerance = 0.175, presupuesto \(B = \$1\text{M}\) y la misma estructura de costos. - Evaluar el funded set resultante sobre el OOT con métricas exactas: retorno realizado, \(V = \sum_i w_i Z_i\), \(\Gamma_{\text{CP}}\) y \(\text{violation} = \max(0, \sum_i w_i u_i - \tau)\).
- Construir la frontera Pareto retorno vs cobertura vs ancho como evidencia empírica de la palanca económica de \(\alpha\).
alpha_sweep_pareto_both.parquet no es una nueva selección de champion. Es un artefacto de sensibilidad que explica la geometría cobertura-ancho al mover \(\alpha\). Las métricas oficiales del CRPTO siguen ancladas en models/final_project_promotion.json::conformal_upstream.winner_metrics y en la evaluación exacta 276k. Esta separación evita mezclar familias: el sweep enseña la palanca; la promoción final decide la policy.
La elección operativa de \(\alpha = 0.10\) para el champion oficial responde a tres criterios simultáneos:
- Validez del bound. El champion economic pasa
alpha01_exact_pass = true(incluso a \(\alpha = 0.01\)), por lo que la elección de \(\alpha = 0.10\) para el LP es deliberadamente más conservadora que la garantía nominal del bound. - Composición del funded set. A \(\alpha = 0.05\), el LP encuentra menos préstamos elegibles porque las cotas son más anchas; a \(\alpha = 0.10\) la frontera Pareto se ubica en la esquina retorno-cobertura útil.
- Convención regulatoria. Cobertura nominal del 90% es el estándar IFRS9 para intervalos de incertidumbre y MAPIE lo usa por defecto, lo que facilita la lectura por comité.
La frontera de Figura 7.2 evidencia esa elección: el codo entre eligibilidad y ancho está alrededor de \(\alpha = 0.10\), donde el LP mantiene flexibilidad sin sacrificar protección.
7.0.8 Estabilidad bajo distributional shift
El test set OOT (2018–2020) contiene un cambio de régimen natural: la tasa de default cae de 24.5% (2018 H1) a 1.35% (2020, inicio de COVID). Este gradiente provee un quasi-experimento para evaluar si la calidad de decisión se degrada bajo distributional shift. SPO+ se entrena una sola vez por seed sobre datos 2007–2017 y se evalúa en cada periodo — simulando un despliegue productivo donde el modelo no se recalibra.
| Periodo | N | Default % | Regret SPO+ | Regret 2-Stage | SPO+ mejora | Cobertura 90% | Ancho medio |
|---|---|---|---|---|---|---|---|
| 2018 H1 | 110,839 | 24.5% | 0.0874 | 0.1500 | 41.7% | 92.07% | 0.7639 |
| 2018 H2 | 86,339 | 23.3% | 0.0799 | 0.1621 | 50.7% | 92.07% | 0.7534 |
| 2019 H1 | 50,245 | 20.8% | 0.0816 | 0.1587 | 48.6% | 92.41% | 0.7459 |
| 2019 H2 | 25,160 | 12.4% | 0.0818 | 0.1723 | 52.5% | 95.23% | 0.7455 |
| 2020 | 4,286 | 1.35% | 0.0743 | 0.1752 | 57.6% | 98.58% | 0.6928 |
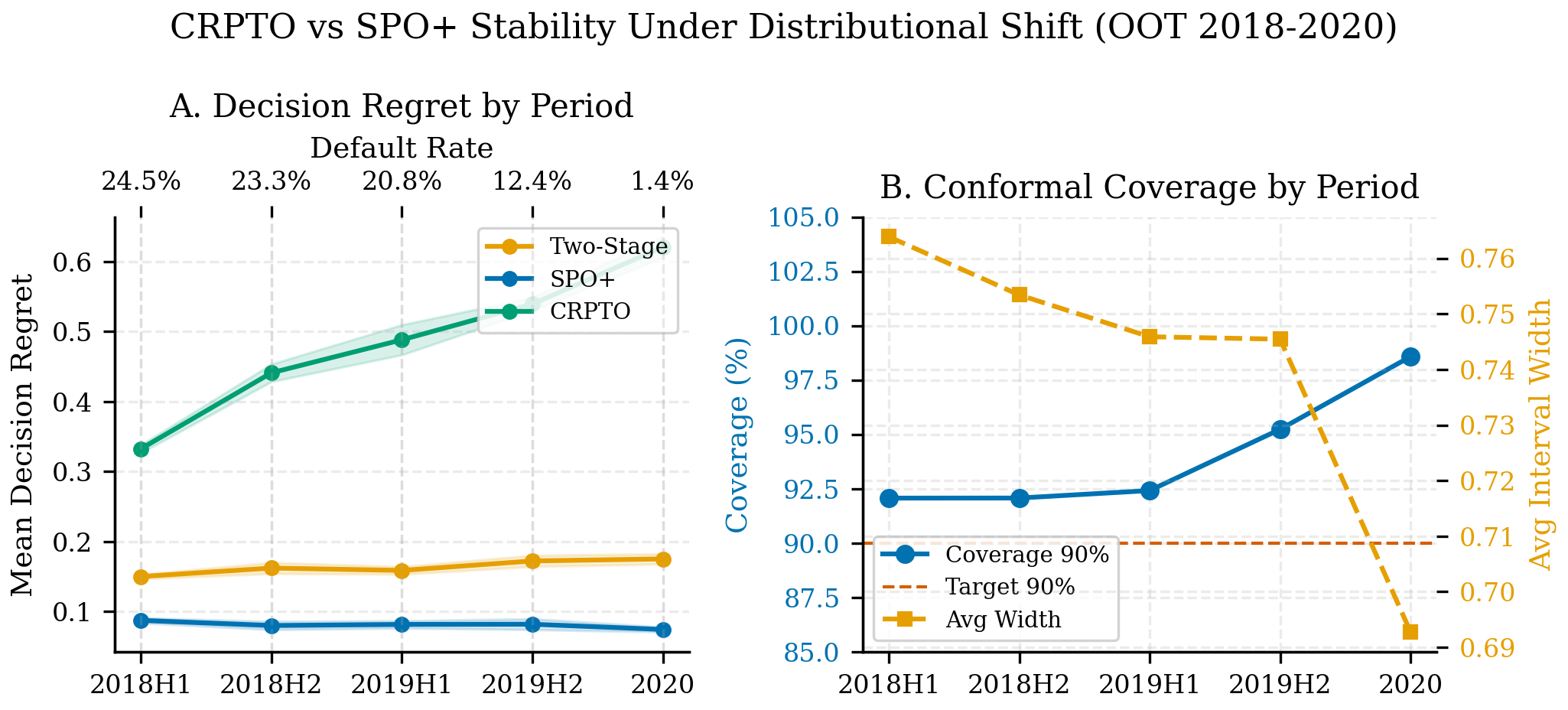
La cobertura conformal se mantiene por encima del target 90% en todos los periodos (rango 92.07%–98.58%), incluyendo el quiebre de régimen COVID. El sobrecumplimiento en 2020 (98.58%) es esperable: menos defaults producen intervalos más conservadores — esta es una propiedad diseñada, no accidental. SPO+ muestra regret estable (0.074–0.087) y su ventaja relativa frente a two-stage incluso crece bajo shift (41.7% → 57.6%), lo cual confirma que SPO+ es un comparador formidable. Sin embargo, esa estabilidad empírica en un dataset no equivale a una garantía formal: un regulador puede verificar que la cobertura conformal se mantuvo; no puede verificar ex ante que el regret de SPO+ se mantendrá bajo el próximo cambio de régimen.
7.0.9 Evidencia P1 añadida para versión journal
La auditoría posterior al cierre del champion agregó una capa P1 reproducible que endurece el paper sin cambiar la policy oficial. Las tablas A3–A6 se regeneran desde scripts/export_crpto_tables.py; las tablas A7–A11, que dependen de solves exactos, se regeneran explícitamente con scripts/analyze_crpto_evidence.py --include-hardening y quedan registradas en models/crpto_evidence_status.json. La primera pieza convierte la historia 5K \(\rightarrow\) 25K \(\rightarrow\) 276K en una lectura post-selección explícita: el 5K detecta existencia, el 25K refina, y el 276K confirma el economic champion en el OOT completo.
La confirmación estrictamente disjunta separa temporalmente el OOT en 2018 y 2019–2020. No es una búsqueda nueva: evalúa la policy congelada en dos slices sin solapamiento. La señal que importa es que ambos slices mantienen alpha01_exact_pass = true, violación cero y funded sets suficientemente distintos como para descartar que el cierre dependa solo de una ventana temporal.
La segunda tabla aplica una lectura tipo CROMS: no selecciona la variante conformal solo por cobertura o anchura, sino que añade compatibilidad con A/B, retorno de la policy tradeoff y métricas exactas del bound. El resultado es conservador pero útil: confirma que score_decile_mondrian es el único finalist que pasa el gate conjunto; las variantes por grade tienen menor ancho, pero fallan cobertura mínima de grupo.
La tabla exacta de finalists completa el punto que faltaba en la primera auditoría: ranks 1, 2 y 3 reciben evaluación bound-aware exacta en el OOT completo. Los tres pasan el bound de portfolio bajo sus policies de tradeoff, pero rank 2 y rank 3 no pasan el gate conformal por cobertura mínima de grupo. Por eso A10 fortalece el selector sin cambiar el conformal winner.
La tercera tabla expande la estabilidad por periodo y grade original. No aparece un segmento oculto por debajo del target 90%; el peor segmento observado es 2018H1/B con cobertura 90.32%, todavía por encima del nivel nominal. Esto fortalece la lectura de gobernanza: la cobertura global no está escondiendo una falla obvia en un corte periodo-segmento.
La exportación per-loan del funded set completa la trazabilidad de composición. La tabla A7 conserva las 341 filas con exposición positiva; el ledger canónico de la frontera reporta n_funded = 340 porque usa un umbral de conteo del solver. Para lectura editorial, A8 resume exposición por periodo y grade. La concentración máxima por segmento queda documentada y permite revisar si el retorno de $170.5K dependía de un corte escondido del funded set.
La tabla de stress sintético repondera el OOT hacia cola de PD, grades E/F/G, periodos tardíos y mezcla de bajo riesgo/COVID. Es un test de covariate shift interno, ahora complementado por la réplica externa A25–A34, y sirve como puente hacia MDCP y conformal online: bajo todas las reponderaciones, la cobertura ponderada al 90% se mantiene sobre el target.
El stress endurecido agrega perturbaciones adversariales de labels: convierte una fracción de no-defaults en defaults en la cola de PD, grades E/F/G, periodos tardíos y el segmento más débil observado. Esto no simula una fuente externa completa; esa pieza queda cubierta por Prosper/Freddie en Capítulo 9. Su función es responder a una crítica complementaria: incluso cuando forzamos defaults adicionales en cortes relevantes, la cobertura 90% permanece por encima del target.
7.0.10 Lectura del conjunto de resultados
El hallazgo defendible ya no es “la robustez siempre gana”. Es más preciso:
- la incertidumbre conformal es suficientemente estable para entrar al optimizador;
- frente a baselines alternativos, produce un conjunto más usable;
- la monotonicidad, la calibración y la gobernanza vuelven el stack defendible ante auditoría y comité;
- la calidad de la policy depende de cómo se negocia tightness del bound contra retorno dentro de una región robusta ya validada.
Ese matiz hace al paper más creíble y más útil para venues de OR o analytics aplicada.