14 Protocolo SPO+ y Lectura del Regret
14.1 Protocolo del Comparador SPO+
El punto de referencia frente a CRPTO tiene dos superficies compatibles, pero no intercambiables: el artefacto local A19/Figura 15 reporta 49.09% de reducción de regret (0.425896 a 0.216837), mientras el rerun pareado PyEPO 1.3.7 curado el 2026-05-28 reporta 48.51% (0.358073 a 0.184366). El resultado histórico estaba cerca del 49%; el cierre final conserva la misma lectura editorial, pero deja el comparador trazado como evidencia de appendix, no como dependencia nueva del champion. Un revisor exigente preguntará lo correcto: ¿cómo se midió eso, con cuántas semillas, sobre qué arquitectura, con qué definición de regret y bajo qué distribución de costos? Esta página documenta el protocolo completo para que ambos números sean defendibles y, sobre todo, para que la comparación con CRPTO se lea correctamente: SPO+ gana en regret porque está diseñado para ganar en regret, no porque sea un sustituto de la garantía conformal.
14.1.1 Versión del protocolo: por qué SPO+ v2
La primera implementación (v1) reportaba apenas 2.5% de mejora sobre two-stage, un número que no justificaba el esfuerzo de end-to-end. La auditoría de marzo 2026 identificó cinco defectos arquitectónicos que explicaban el resultado pobre y que corresponden punto por punto a la versión v2 que el paper cita:
| # | Defecto en v1 | Corrección en v2 | Por qué importa |
|---|---|---|---|
| 1 | MLP plano sobre input 500-dim concatenado | MLP point-wise permutation-equivariant sobre input 10-dim por loan | El optimizador combinatorio es invariante a permutación de items; un MLP plano rompe esa simetría y desperdicia capacidad. |
| 2 | Costos binarios (default/no default) | Costos continuos calibrados desde la PD Venn-Abers | Costos binarios producen un paisaje de pérdida casi plano; los gradientes SPO+ se desvanecen y la red no aprende. |
| 3 | Una sola semilla | 5 semillas independientes | La varianza inter-seed es la mayor fuente de ruido; un solo número podría ser suerte. |
| 4 | Sólo two-stage como comparador | Tres métodos: two-stage, SPO+, conformal robust | Sin el tercer comparador, la lectura “auditabilidad vs regret” no aparece. |
| 5 | n_items = 50 |
n_items = 100 en la versión train; n_items = 50 mantenido para evaluación temporal |
Más items por instancia LP → gradientes más informativos; evaluación temporal mantiene budget=15 para comparabilidad. |
14.1.2 Configuración exacta de las corridas v2
La distinción es deliberada. El número A19 49.09% pertenece al artefacto local n_items=100, budget=30; el número PyEPO 48.51% pertenece al closeout pareado curado (PyEPO 1.3.7) bajo una reconstrucción posterior del protocolo. La tabla temporal usa n_items=50, budget=15 para mantener comparabilidad por periodo OOT y conectar regret con cobertura conformal bajo shift. Mezclar esas configuraciones en una sola frase sería confuso; separarlas vuelve el comparador más defendible.
El repo no importa la suite PyEPO completa ni crea una dependencia nueva. El dossier local docs/research/crpto_pyepo_dfl_intake_2026-05-26.md conserva solo el cierre necesario para el appendix: SPO+ obtiene mean regret 0.184366 frente a 0.358073 para two-stage, una reducción de 48.51% con Wilcoxon pareado p = 3.80e-163. RFYL y CaVE quedan como evidencia de agenda extendida CRPTO/tesis; CRPTO sigue siendo el método de cobertura robusta y auditabilidad.
14.1.3 Estabilidad temporal: SPO+ y la cobertura conformal bajo shift
El test set OOT 2018–2020 contiene un quiebre natural de régimen: la tasa de default cae de 24.46% (2018H1) a 1.35% (2020, inicio COVID). Ese gradiente provee un quasi-experimento donde SPO+ se entrena una sola vez sobre 2007–2017 y se evalúa en cada periodo sin recalibración, simulando un despliegue real.
Las dos lecturas correctas de la tabla son simultáneas y no contradictorias:
SPO+ es un comparador formidable. Su regret se mantiene en el rango
[0.0743, 0.0874]a través de cinco periodos OOT, y su mejora relativa frente a two-stage incluso crece con el shift (41.73% → 57.56%). Eso confirma la tesis original de Elmachtoub & Grigas: entrenar end-to-end para la decisión sí produce mejores decisiones.La cobertura conformal se mantiene por encima del target en todos los periodos (
{python} f"{summary['coverage_range'][0]*100:.2f}%"–{python} f"{summary['coverage_range'][1]*100:.2f}%"), incluyendo el quiebre COVID. La sobre-cobertura en 2020 (98.58%) es una propiedad diseñada, no accidental: con default rate cayendo a 1.35%, los intervalos sobre la mayoría de loans cubren ampliamente.
La distinción importante es esta: la estabilidad de SPO+ en este dataset es empírica y bonita, pero un regulador no puede auditar ex ante que el regret se mantendrá en el siguiente cambio de régimen. La cobertura conformal sí se puede auditar — está construida para sobrevivir intercambiabilidad incluso bajo shift.
14.1.4 Lectura editorial de los dos números SPO+
El número de A19/Figura 15 (49.09%, Wilcoxon \(p = 1.39\times10^{-164}\)) viene del artefacto local models/spo_real_training_status.json. El número del closeout PyEPO (48.51%, Wilcoxon \(p = 3.80\times10^{-163}\) sobre 1,000 instancias pareadas) viene del rerun curado 2026-05-28. Las cifras son consistentes pero no idénticas porque corresponden a protocolos distintos y cumplen roles distintos:
| Número | Origen | Rol en el paper |
|---|---|---|
| 49.09% reducción de regret | A19/Figura 15, models/spo_real_training_status.json, 5 seeds, n_items=100 |
Número canónico para el cuerpo cuando se cita la frontera regret-auditability |
| 48.51% reducción de regret | Closeout pareado PyEPO 1.3.7, 1,000 instancias, 5 seeds, n_items=100 |
Evidencia de cierre curada; corrobora el claim, pero no reemplaza A19 |
| 41.73%–57.56% mejora por periodo | Eval temporal OOT, 5 periodos, n_items=50 |
Soporta el claim “la ventaja se preserva bajo shift” |
| Wilcoxon \(p = 1.39\times10^{-164}\) / \(3.80\times10^{-163}\) | Tests pareados de A19 y PyEPO closeout | Robustece estadísticamente ambos protocolos |
14.1.5 Por qué CRPTO no compite en regret y por qué eso no es una derrota
La métrica de regret aquí es decisión regret: la pérdida de elegir la acción óptima bajo costos predichos versus elegir la acción óptima bajo costos verdaderos, evaluada sobre la distribución verdadera. SPO+ minimiza esa cantidad por diseño — su gradiente es exactamente el subdiferencial del SPO loss, y las arquitecturas v2 (point-wise equivariant, costos calibrados) le dan al optimizador toda la información correcta.
CRPTO no participa en ese juego. CRPTO pega la cota superior conformal \(u_i = p_i^H(\alpha)\) a la restricción de PD ponderada del LP y luego maximiza retorno sujeto a esa restricción. Eso produce, por construcción, una decisión más conservadora que la del SPO+ — y por lo tanto un regret más alto en el sentido decisional puro. La métrica de éxito de CRPTO es otra: la garantía de cobertura del intervalo, que el regulador puede verificar empíricamente periodo a periodo.
Concretamente, la regla del paper es:
- Si la pregunta es “¿qué método minimiza regret en este dataset bajo este protocolo?”, SPO+ gana, y el paper lo dice explícitamente.
- Si la pregunta es “¿qué método ofrece una garantía formal auditable bajo cambio de régimen?”, CRPTO gana, y la cobertura mantenida en los 5 periodos OOT es la evidencia (no un torneo aislado).
Esa simetría entre fortalezas es la contribución editorial más importante del comparador SPO+ en el CRPTO, y por eso 14e-discussion debe leerse con esta página como anexo técnico de soporte.
14.1.6 Frontera regret-auditability para el paper
La versión journal materializa esa simetria en la tabla A19 y la Figura Figura 14.1. La regla de lectura es simple: SPO+ ocupa la esquina de menor regret, mientras CRPTO ocupa la esquina de controles de riesgo verificables. El eje vertical no es un score subjetivo; cuenta tres checks que un reviewer puede auditar desde artefactos congelados: cobertura temporal sobre target, bound exacto del funded set y región robusta 45/45.
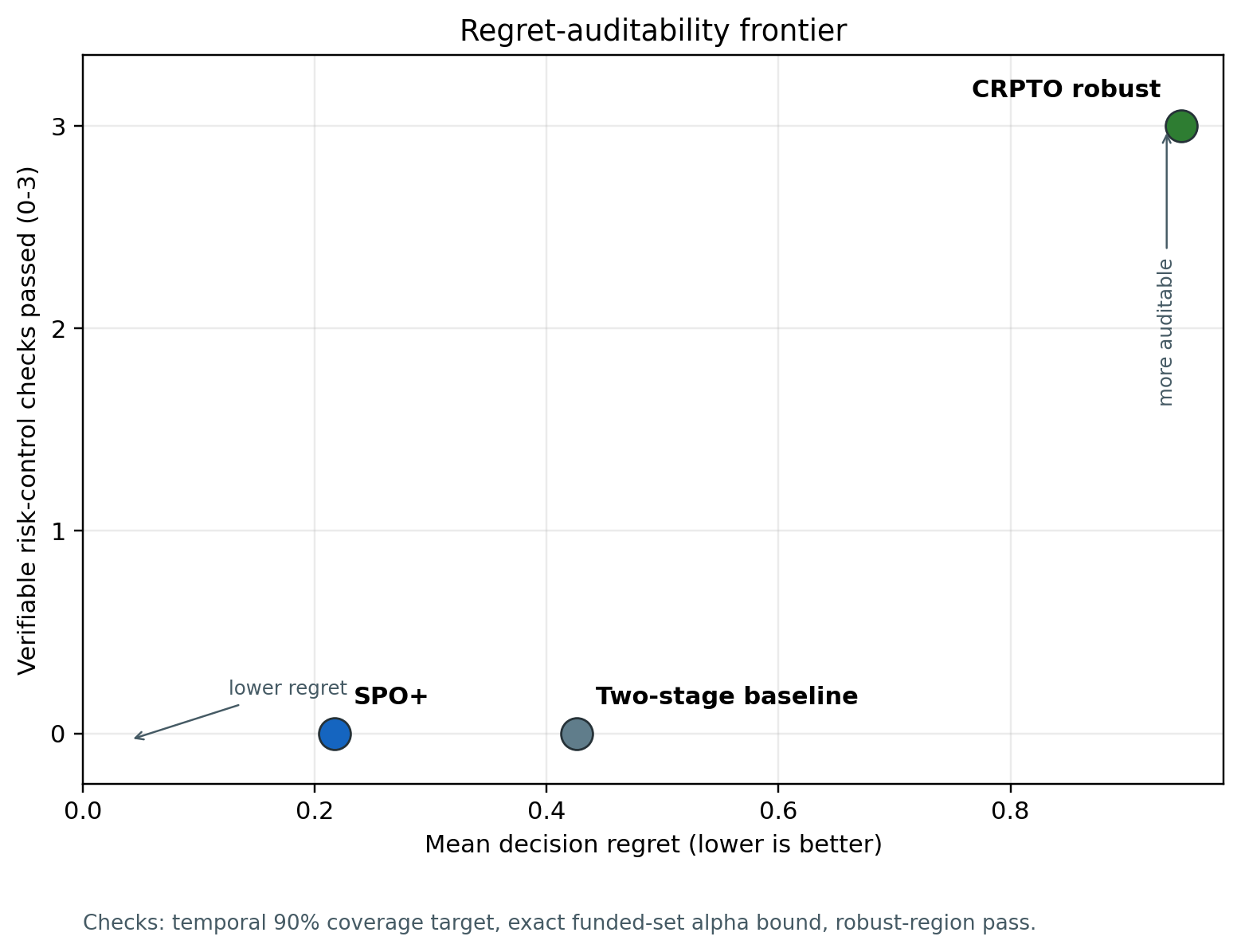
Esta figura permite decir en el cuerpo del paper que CRPTO no intenta ganar el torneo de regret puro. La historia publicable es más fuerte: cuando un comité necesita cobertura, exact bound y trazabilidad del funded set, el costo en regret se vuelve explícito.
Posicionamiento frente a la teoría general de la frontera
Un revisor que conozca la literatura reciente notará que existe una línea que da garantías distribution-free y de muestra finita conjuntas sobre miscoverage y regret, trazando la frontera de Pareto miscoverage–regret para familias de políticas robust predict-then-optimize (Zhou et al., 2025; Zhou & Zhu, 2026). Esa línea es la teoría general de la frontera que la Figura Figura 14.1 dibuja: muestra cómo calibrar un nivel de robustez contra una preferencia costo–riesgo en una familia de optimización abstracta. CRPTO es el objeto complementario y aplicado. No propone un nuevo estimador de frontera; instancia una esquina de esa frontera sobre un artefacto de riesgo de crédito congelado y de estilo productivo, con un premio de robustez conformal nombrado (\(\Gamma_{\mathrm{CP}}\)), un certificado exacto del funded set, auditoría por grade y trazabilidad de model risk que un comité puede inspeccionar. La distinción que conviene declarar explícitamente: CRPTO no compite con esa teoría en generalidad; la aterriza en una decisión de cartera de crédito auditable sobre Lending Club. Esto convierte un vecino teórico cercano en un apoyo, no en una amenaza al claim.
14.1.7 Reproducibilidad
uv run python scripts/run_spo_real.py
uv run python scripts/run_spo_comparison.py
uv run pytest tests/ -k "spo or stability"Los artefactos clave son:
data/processed/crpto_vs_spo_stability.json— métricas agregadas por periodo y rango de mejora.data/processed/crpto_vs_spo_stability_detail.parquet— regret por seed y periodo (para reanalizar varianza).data/processed/spo_training_loss.parquet— curva de pérdida SPO+ durante entrenamiento.models/spo_real_training_status.json— estado del run v2 (schema2026-03-17.2).docs/research/crpto_pyepo_dfl_intake_2026-05-26.md— cierre curado 2026-05-28 del rerun PyEPO 1.3.7.reports/crpto/extended/crpto_extended_pyepo_dfl_full_summary_20260528.csv— tabla curada de la suite DFL completa para tesis/appendix, sin logs ni dependencias pesadas.
14.1.8 Cierre: el carril DFL formal con PyEPO 1.3.7
Esta sección es cierre curado, no promoción de un método nuevo. El comparador SPO+ que el paper cita ya es defendible con los artefactos congelados y con la nota PyEPO 1.3.7 documentada en docs/research/crpto_pyepo_dfl_intake_2026-05-26.md, sin re-correr nada ni tocar el champion.
PyEPO 1.3.7 (publicado 2026-05-26) madura el ecosistema de decision-focused learning (Mandi et al., 2024) al punto de habilitar un stack de comparadores DFL aislado y reproducible: ya no depende del antiguo bloqueador cvxpy/cvxpylayers y corre en un entorno OR-Tools opcional. Para la forma actual del problema CRPTO –una selección de portafolio sobre un LP continuo– el método más natural no es SPO+ sino regularizedFrankWolfeFenchelYoung (RFYL), que sólo necesita un oráculo de optimización lineal. Eso da a la agenda extendida CRPTO/tesis un experimento DFL “formal” más creíble que el surrogate oracle-regret anterior.
La frontera de claims es estricta y coincide con la del comparador SPO+:
- Permitido: “PyEPO 1.3.7 habilita un comparador DFL aislado y reproducible”; “RFYL es el método más natural para el LP continuo de selección de crédito”.
- No permitido: “PyEPO reemplaza a CRPTO”; “SPO+/RFYL/CaVE ofrecen garantía de cobertura conformal”. El carril DFL compra amplitud de comparación y auditabilidad de la decisión, no una garantía formal de cobertura –esa sigue siendo la contribución exclusiva de la capa conformal de CRPTO.
La regla de parada ya queda satisfecha para CRPTO: el rerun pareado SPO+ deja el closeout en 48.51%, mientras A19/Figura 15 conserva su 49.09% local; esa diferencia de protocolo no altera el claim central. Los comparadores RFYL, CaVE y PFYL-Mul pertenecen al laboratorio agenda extendida CRPTO/tesis; si no cambian un claim del manuscrito CRPTO ni producen una tabla de comparación más limpia, permanecen fuera del paper IJDS.