5 Marco Teórico
El marco teórico del paper combina tres tradiciones que normalmente se estudian por separado: predicción probabilística calibrada, incertidumbre distribution-free y optimización robusta.
5.0.1 De probabilidad puntual a banda de riesgo
La primera pieza es el intervalo conformal por observación:
\[ \widehat{C}_{1-\alpha}(x,g)=\left[\max\{0,\widehat{p}(x)-q_{1-\alpha,g}\},\min\{1,\widehat{p}(x)+q_{1-\alpha,g}\}\right] \]
donde g representa la partición Mondrian. El objeto importante no es solo la cobertura marginal, sino la posibilidad de traducir la cota superior del intervalo en una versión prudente del riesgo.
5.0.2 Del intervalo al conjunto de incertidumbre
Para portafolio, la lectura operativa es inmediata:
\[ u_i(\alpha)=\sup \widehat{C}_{1-\alpha}(x_i,g_i) \]
Ese \(u_i\) funciona como probabilidad de default en peor caso admisible bajo el nivel conformal elegido. En lugar de construir un conjunto elipsoidal o bootstrap exógeno, el conjunto nace de la propia capa predictiva.
5.0.3 Optimización robusta
El portafolio robusto puede expresarse, de forma esquemática, como:
\[ \max_{z \in \{0,1\}^n}\sum_i z_i\,r_i \quad\text{s.a.}\quad \sum_i z_i a_i \le B,\; \sum_i z_i u_i(\alpha)a_i \le \tau B \]
La restricción de pérdida esperada usa la frontera superior inducida por el intervalo. Así, la robustez deja de ser un parámetro abstracto y pasa a estar anclada a un objeto con garantía empírica de cobertura.
5.0.4 Formalización del vínculo \(\alpha \leftrightarrow \Gamma\)
La intuición del pipeline es directa: a menor \(\alpha\) (mayor confianza), los intervalos se ensanchan, \(u_i\) sube y la restricción robusta se endurece. Pero una intuición no es un teorema. Esta sección formaliza esa correspondencia y establece garantías probabilísticas sobre la no cobertura ponderada del funded set. Cuando el texto habla de PD verdadera debe leerse como una interpretación latente adicional, no como una magnitud observada directamente en los artefactos.
Antes de entrar al detalle, conviene ubicar el resultado frente a cinco tradiciones que el bound CRPTO toca de forma simultánea. La optimización robusta clásica (Bertsimas et al., 2018; Bertsimas & Kallus, 2020; Bertsimas & Sim, 2004) enseña a proteger una decisión contra un conjunto de incertidumbre, pero deja al analista la pregunta incómoda de qué tamaño darle a ese conjunto. La familia conformal \(\rightarrow\) robust optimization (Johnstone & Cox, 2021; Patel et al., 2024; Zhao et al., 2026) responde esa pregunta haciendo que el conjunto herede una garantía de cobertura distribution-free, mientras que predict-then-calibrate (Sun et al., 2024) muestra que predicción y calibración pueden separarse para un LP contextual sin restringir el modelo base. El control de riesgo conformal (Angelopoulos et al., 2024; Angelopoulos et al., 2025; Bates et al., 2021) generaliza la cobertura marginal hacia el control de pérdidas o riesgos definidos por el usuario. La literatura de conformal decisión risk (Kiyani et al., 2025; Lekeufack et al., 2023; Zhou et al., 2025; Zhou & Zhu, 2026) calibra decisiones o certificados de robustez directamente, y los trabajos de weighted/localized/multi-distribution CP (Barber et al., 2023; Bhattacharyya & Barber, 2026; Guan, 2023; Tibshirani et al., 2019; Yang & Jin, 2026) delimitan cuándo una garantía marginal puede leerse sobre subconjuntos, pesos o distribuciones no idénticas.
El Teorema 1 hereda el espíritu de control de riesgo de esa última familia, pero lo instancia en una dirección que ninguno de esos trabajos aterriza: la pérdida no es un error genérico de predicción ni la simple membresía del parámetro en un set, sino la no cobertura ponderada por funded set \(V\) que aparece al mapear intervalos conformales Mondrian a una restricción lineal de PD del portafolio de crédito. Esa especialización es la que permite cerrar el bound de forma exacta (\(\alpha=0.01\)) sobre una región robusta completa y leerlo con cantidades auditables (\(V\), \(\Gamma_{\text{CP}}\), violation). La Tabla 5.1 ubica el aporte trabajo por trabajo.
| Trabajo | Objeto garantizado | Vínculo con la decisión | Diferencia con CRPTO |
|---|---|---|---|
| (Bertsimas & Sim, 2004) | Factibilidad robusta dado un presupuesto \(\Gamma\) elegido por el analista | Optimización robusta clásica sobre un conjunto poliédrico | Aquí \(\Gamma_{\text{CP}}\) no se elige por convención: se hereda del cuantil conformal de la capa de incertidumbre. |
| (Bertsimas et al., 2018; Bertsimas & Kallus, 2020) | Decisiones prescriptivas y conjuntos de incertidumbre aprendidos de datos | Data-driven RO / prescriptive analytics | CRPTO usa esa lógica predict-then-optimize, pero el tamaño operativo del set viene de cobertura conformal y se audita en el funded set. |
| (Johnstone & Cox, 2021) | Conjuntos elipsoidales con validez finita (distancia de Mahalanobis como score) | Puente CP \(\rightarrow\) RO para regresión multi-objetivo | Set genérico de membresía; no aterriza una restricción de PD ponderada por funded set ni cobertura por grupo en crédito. |
| (Patel et al., 2024) | Regiones conformales no convexas de alta dimensión vía modelos generativos condicionales | Predict-then-optimize contextual (CPO) con cobertura distribution-free | Cubre el vector de parámetros del problema; CRPTO controla la no-cobertura ponderada de un target acotado de cartera, no la membresía en un set. |
| (Sun et al., 2024) | Cobertura del vector de costos por calibración post-hoc, independiente del modelo predictivo | Separación predict-then-calibrate para LP contextual robusto y DRO | Garantiza \(c \in \mathcal{U}\); CRPTO conecta esa cobertura con una cota Markov sobre la violación del portafolio y un cierre exacto del funded set. |
| (Zhao et al., 2026) | Sets calibrados context-dependent con cobertura finita \(O(n^{-1/2})\) y equivalencia CRO \(\equiv\) satisficing (CRS) | Optimización y satisficing robustos sobre predictores black-box | CRS hace del satisficing el objetivo; en CRPTO el satisficing es diagnóstico (A13/A20) y el aporte es el bound portfolio-aware con cierre exacto en crédito. |
| (Hu et al., 2026) | Robustez controlada directamente, no solo cobertura del conjunto | Conformal Robustness Control para decisiones menos conservadoras | Vecino muy cercano: CRPTO no optimiza el set para robustez; conserva calibración post-hoc auditable y valida exactitud del funded set promovido. |
| (Bao et al., 2025) | Selección óptima del modelo conformal bajo criterio de optimización robusta (CROMS) | Elige el conjunto conformal que mejor sirve a la decisión | CRPTO ya usa un selector decision-aware (A5) y eval exacta de ranks 1–3 (A10), pero su contribución central es el bound y la región robusta exacta, no la selección de modelo. |
| (Angelopoulos et al., 2025; Bates et al., 2021) | Control distribution-free de una pérdida o riesgo genérico definido por el usuario | Calibración post-hoc de un parámetro de riesgo (RCPS/LTT) | No se especializa a una restricción lineal de portafolio ni a un funded set ponderado. |
| (Angelopoulos et al., 2024) | Cota en esperanza para cualquier pérdida monotónica acotada (conformal risk control) | Conformal risk control general | Nuestro Teorema 1 es una instanciación portfolio-aware de CRC con funded set ponderado, cierre exacto y cobertura Mondrian. |
| (Chenreddy & Delage, 2024; Yeh et al., 2025) | Entrenamiento/calibración end-to-end con pérdida de decisión aguas abajo | Cierra el ciclo predicción-calibración-decisión | CRPTO es deliberadamente post-hoc y auditable: no entrena la calibración sobre la decisión (eso queda como extensión journal). |
| (Kiyani et al., 2025; Lekeufack et al., 2023) | Políticas seguras o risk-averse derivadas de sets/predicciones conformales | Fundamentos decision-theoretic para usar incertidumbre en acciones | Dan el puente conceptual predicción \(\rightarrow\) decisión; CRPTO lo instancia en una restricción de PD de cartera y evidencia crediticia OOT. |
| (Zhou et al., 2025; Zhou & Zhu, 2026) | Certificados conformalizados de riesgo/robustez de decisión | Evalúan o calibran robustez/regret de familias de políticas | Muy relevantes para CRPTO v2; el champion actual no usa calibración inversa ni certificados para seleccionar la policy. |
| (Barber et al., 2023; Bhattacharyya & Barber, 2026; Guan, 2023; Tibshirani et al., 2019; Yang & Jin, 2026) | Cobertura bajo pesos, localización, selección de grupos o múltiples distribuciones | Delimita cuándo una garantía conformal sigue siendo válida tras ponderar/subseleccionar | Justifican la cautela editorial: el bound formal requiere validez ponderada del funded set; A23/A24 son diagnósticos, no claims de recalibración live. |
| Este paper (CRPTO) | Factibilidad conformal del portafolio vía \(V\), \(\Gamma_{\text{CP}}\) y violation, con cierre exacto \(\alpha=0.01\) sobre una región robusta completa |
Score calibrado \(\rightarrow\) intervalo Mondrian \(\rightarrow\) funded set robusto promovido | Aporta la instanciación en crédito minorista, la cota Markov sobre la violación ponderada y la cobertura Mondrian grupo-condicional. |
La lectura conjunta de la tabla es que CRPTO no compite por inventar un conjunto de incertidumbre más general, sino por especializar el control de riesgo conformal a la restricción exacta que mueve la decisión de crédito: ningún vecino combina, a la vez, una restricción de PD ponderada por el funded set real, una cota distribution-free sobre la violación del portafolio y cobertura grupo-condicional Mondrian sobre un cierre empírico exacto.
El artefacto scripts/validate_alpha_gamma_bound.py evalúa no cobertura ponderada usando el target observado y_true/default_flag contra la cota superior conformal. Por tanto, la garantía distribution-free del teorema controla un target acotado \(Y_i \in [0,1]\) y una asignación fijada antes de observar \(Y_i\). Interpretar \(Y_i\) como PD latente requiere el supuesto adicional de que \(u_i\) es una cota válida de esa PD latente. El cierre exacto 276k valida empíricamente la policy promovida tras la búsqueda; no convierte esa validación post-selección en una garantía conformal más fuerte.
El paso desde cobertura marginal hacia \(V=\sum_i w_iZ_i\) requiere además una condición de validez ponderada para el funded set: los pesos elegidos por el optimizador no deben concentrarse en una región con no cobertura peor que la nominal, salvo que esa región esté cubierta por una garantía Mondrian, weighted/localized o multi-distribution explícita. En CRPTO esa condición se declara como supuesto formal y se respalda empíricamente con el cierre exacto 276k, la región robusta 45/45, A23 y A24.
La lectura final del bound se organiza en tres piezas, que conviene mantener separadas tanto en el libro como en el paper IJDS:
| Pieza | Qué afirma | Qué no afirma |
|---|---|---|
| Identidad determinística | Si el funded set cumple \(\sum_i w_i u_i \leq \tau\), cualquier exceso realizado sobre \(\tau\) entra por \(V=\sum_iw_i\mathbf{1}\{Y_i>u_i\}\). | No necesita una garantía conformal ni prueba por distribución. |
| Supuesto estadístico ponderado | Para convertir la identidad en bound probabilístico se asume \(\mathbb{E}[V]\leq\alpha\) sobre la población ponderada por el funded set. | Split conformal marginal por sí solo no controla cualquier subportafolio adaptativo. |
| Certificado empírico CRPTO | El champion rebaselined pasa exactamente: \(V=0.028875\), \(\Gamma_{\text{CP}}=0.187987\), violation=0, región robusta 45/45. |
El cierre post-selección no crea una garantía conformal universal ni prospectiva. |
Presupuesto conformal de robustez
Definición 5.1 (Presupuesto conformal de robustez) Sea \(x^*\) la asignación óptima del LP robusto con pesos normalizados \(w_i = x_i^* a_i / \sum_j x_j^* a_j\) y cotas superiores conformales \(u_i \equiv u_i(\alpha)=\min\{1,\widehat{p}_i+q_{1-\alpha,g_i}\}\). El presupuesto conformal de robustez para una asignación \(w\) es:
\[ \Gamma_{\text{CP}}(\alpha;w) = \sum_{i} w_i \cdot \bigl(u_i(\alpha) - \widehat{p}_i\bigr) = \sum_{i} w_i \cdot \min\{q_{1-\alpha,\,g_i},\,1-\widehat{p}_i\} \tag{5.1}\]
donde \(q_{1-\alpha,g_i}\) es el cuantil conformal de scores de no conformidad en el grupo Mondrian \(g_i\). Cuando no hay clipping superior en uno, la última expresión se reduce a \(\sum_i w_iq_{1-\alpha,g_i}\).
\(\Gamma_{\text{CP}}\) mide la prima promedio ponderada de PD que el portafolio paga por protegerse contra la incertidumbre, después de fijar la asignación. Es el análogo conformal del presupuesto \(\Gamma\) de Bertsimas y Sim (2004), pero con una diferencia fundamental: su tamaño no se elige por convención o calibración experta, sino que se hereda directamente de la garantía de cobertura del intervalo conformal.
Proposición 1: Monotonicidad
Proposición 5.1 (Monotonicidad del presupuesto conformal) Para una asignación fija \(w\), \(\Gamma_{\text{CP}}(\alpha;w)\) es monótonamente no creciente en \(\alpha\). A menor \(\alpha\) (mayor confianza conformal), el presupuesto de robustez aumenta.
Demostración. El cuantil \(q_{1-\alpha,g}\) es la función cuantil evaluada en el nivel \(1-\alpha\) de la distribución empírica de scores de no conformidad del grupo \(g\). La función cuantil es no decreciente, por lo que \(q_{1-\alpha,g}\) es no decreciente en \((1-\alpha)\), equivalentemente no creciente en \(\alpha\). El término con clipping \(\min\{q_{1-\alpha,g_i},1-\widehat{p}_i\}\) preserva esa monotonicidad. Dado que \(\Gamma_{\text{CP}}(\alpha;w)\) es una suma ponderada con pesos no negativos fijos, hereda la monotonicidad. \(\square\)
La consecuencia práctica es inmediata: si un gestor decide endurecer la protección de 90% a 95% sin cambiar el funded set, el presupuesto de robustez crece de forma predecible — y con él, el costo económico de la protección. Cuando el optimizador se vuelve a resolver para cada \(\alpha\), los pesos cambian a \(w(\alpha)\); en ese caso la monotonicidad de \(\Gamma_{\text{CP}}(\alpha;w(\alpha))\) es una propiedad empírica del cierre, no una consecuencia automática de la proposición.
Proposición 2: Embedding en Bertsimas-Sim
Proposición 5.2 (Embedding del conjunto conformal en Bertsimas-Sim) El conjunto de incertidumbre box conformal \(\mathcal{U}_{\text{CP}}(\alpha) = \{p : p_i \leq u_i(\alpha)\;\forall i\}\) se embebe en el conjunto de Bertsimas-Sim con presupuesto \(\Gamma_{\text{BS}} = n\) y desviaciones \(\hat{\delta}_i = q_{1-\alpha,g_i}\). Sin embargo, la garantía conformal implica que el número esperado de desviaciones simultáneamente activas es como máximo \(n\alpha\), induciendo un presupuesto efectivo \(\Gamma_{\text{eff}} = n\alpha \ll n\).
Demostración. En el marco de Bertsimas-Sim, el conjunto de incertidumbre es \(\mathcal{U}_{\text{BS}} = \{\tilde{a} : |\tilde{a}_i - \hat{a}_i| \leq \hat{\delta}_i,\;\sum_i |\tilde{a}_i - \hat{a}_i|/\hat{\delta}_i \leq \Gamma\}\). Con \(\Gamma = n\), la restricción de presupuesto se vuelve no activa (todos los coeficientes pueden desviarse al máximo simultáneamente), recuperando el conjunto box. Para la lectura de presupuesto efectivo: sea \(Z_i = \mathbf{1}\{Y_i > u_i\}\) el indicador de no cobertura del target acotado. Bajo una muestra test intercambiable y antes de cualquier selección adaptativa por labels, la garantía conformal marginal implica \(\mathbb{E}[\sum_i Z_i] \leq n\alpha\). Para el funded set seleccionado, la versión que usa el teorema es la ponderada: \(\mathbb{E}[\sum_i w_iZ_i]\leq\alpha\) bajo la condición de validez ponderada declarada abajo. \(\square\)
Para el cierre final del proyecto, la interpretación correcta ya no es la de un único portafolio congelado de 299 préstamos, sino la de una región robusta evaluada sobre el OOT completo de 276,869 préstamos. La intuición de presupuesto efectivo sigue siendo válida, pero ahora debe leerse así: el conjunto conformal induce un presupuesto de desviación esperada que luego es filtrado por la composición del funded set. El hallazgo empírico importante es que una policy bien elegida puede reducir ese presupuesto efectivo de forma sustancial aún manteniendo retorno alto.
Teorema 1: Garantía conformal de factibilidad
Teorema 5.1 (Garantía conformal de factibilidad del portafolio) Sea \(Y_i \in [0,1]\) el target de riesgo cubierto por el intervalo conformal; en los artefactos del proyecto, \(Y_i\) corresponde al default observado usado como proxy ex post. Sea \(x^*\) una asignación fijada antes de observar \(Y_i\), con pesos normalizados \(w_i = x_i^* a_i / \sum_j x_j^* a_j\), y cotas conformales \(u_i \equiv u_i(\alpha)\) tales que \(\sum_i w_i u_i \leq \tau\). Bajo intercambiabilidad entre calibración y test, tratando la asignación como fija respecto a los labels evaluados, y asumiendo validez ponderada del funded set,
\[ \mathbb{E}\!\left[V \mid \mathcal{F}_{cal}, w\right] = \mathbb{E}\!\left[\sum_i w_i\mathbf{1}\{Y_i>u_i\}\mid \mathcal{F}_{cal}, w\right] \leq \alpha, \]
se cumple:
(a) La violación esperada de la restricción está acotada por \(\alpha\):
\[ \mathbb{E}\!\left[\max\!\left(0,\;\sum_i w_i\, Y_i - \tau\right)\right] \leq \alpha \tag{5.2}\]
(b) Para cualquier \(t > 0\), la probabilidad de violación está acotada:
\[ \mathbb{P}\!\left(\sum_i w_i\, Y_i > \tau + t\right) \leq \frac{\alpha}{t} \tag{5.3}\]
(c) Evaluando en \(t = \sqrt{\alpha}\) (el punto que iguala umbral y cola en el paso de Markov):
\[ \mathbb{P}\!\left(\sum_i w_i\, Y_i > \tau + \sqrt{\alpha}\right) \leq \sqrt{\alpha} \tag{5.4}\]
Demostración. La estructura de la prueba es la misma que el control distribution-free de pérdidas monotónicas acotadas en (Angelopoulos et al., 2024) y RCPS en (Bates et al., 2021), pero instanciada sobre una pérdida específica al portafolio: la no-cobertura ponderada por funded set. Esa especialización es lo que hace que la garantía conformal del intervalo se herede de forma directa hacia la factibilidad del LP robusto. La prueba descansa en descomponer el target de riesgo ponderado usando indicadores de cobertura.
Paso 1 (Descomposición). Sea \(Z_i = \mathbf{1}\{Y_i > u_i\}\). Para los préstamos cubiertos (\(Z_i = 0\)), \(Y_i \leq u_i\). Para los no cubiertos (\(Z_i = 1\)), \(Y_i \leq 1\) (cota trivial ya que \(Y_i \in [0,1]\)), de modo que \(Y_i - u_i \leq 1\). Entonces:
\[ \sum_i w_i\, Y_i = \sum_i w_i\, Y_i\,(1-Z_i) + \sum_i w_i\, Y_i\, Z_i \leq \sum_i w_i\, u_i + \sum_i w_i\, Z_i \leq \tau + V \]
donde \(V = \sum_i w_i Z_i\) es la no cobertura ponderada.
Paso 2 (Cota de la esperanza). Por la condición de validez ponderada del funded set,
\[ \mathbb{E}[V \mid \mathcal{F}_{cal},w] = \mathbb{E}\!\left[\sum_i w_iZ_i\mid \mathcal{F}_{cal},w\right] \leq \alpha. \]
Esta condición se obtiene directamente si los pesos son fijos/no adaptativos frente a los labels evaluados y la garantía conformal aplica de forma uniforme a la población ponderada relevante. Bajo Mondrian o weighted conformal, puede refinarse como \(\mathbb{E}[V]\leq\sum_g W_g\alpha_g\), con \(W_g=\sum_{i\in g}w_i\).
Paso 3 (Resultados). La parte (a) sigue de \(\mathbb{E}[\max(0, \sum w_i Y_i - \tau)] \leq \mathbb{E}[V] \leq \alpha\). La parte (b) aplica la desigualdad de Markov a \(V\): \(\mathbb{P}(V > t) \leq \mathbb{E}[V]/t \leq \alpha/t\). La parte (c) sustituye \(t = \sqrt{\alpha}\). \(\square\)
La elección \(t = \sqrt{\alpha}\) es por interpretabilidad, no por optimalidad global: deja el umbral una potencia de \(\sqrt{\alpha}\) por encima del nivel nominal y produce la lectura limpia “la miscoverage supera \(\sqrt{\alpha}\) con probabilidad a lo sumo \(\sqrt{\alpha}\)”. Markov usa solo el primer momento de \(V\), de modo que es el argumento más débil defendible: cualquier control de segundo momento o de diferencias acotadas (Chebyshev, Hoeffding o Bernstein) lo aprieta siempre que se cumpla el supuesto adicional de independencia entre clusters. Esos tightenings condicionales viven en el apéndice A21 (crpto_conditional_tightening_appendix), no en el resultado principal, porque la contribución central de CRPTO es la construcción de decisión auditable, no la cota de cola más fina posible. Markov queda como el bound distribution-free principal precisamente porque no exige ese supuesto.
Validación empírica del vínculo \(\alpha \leftrightarrow \Gamma\)
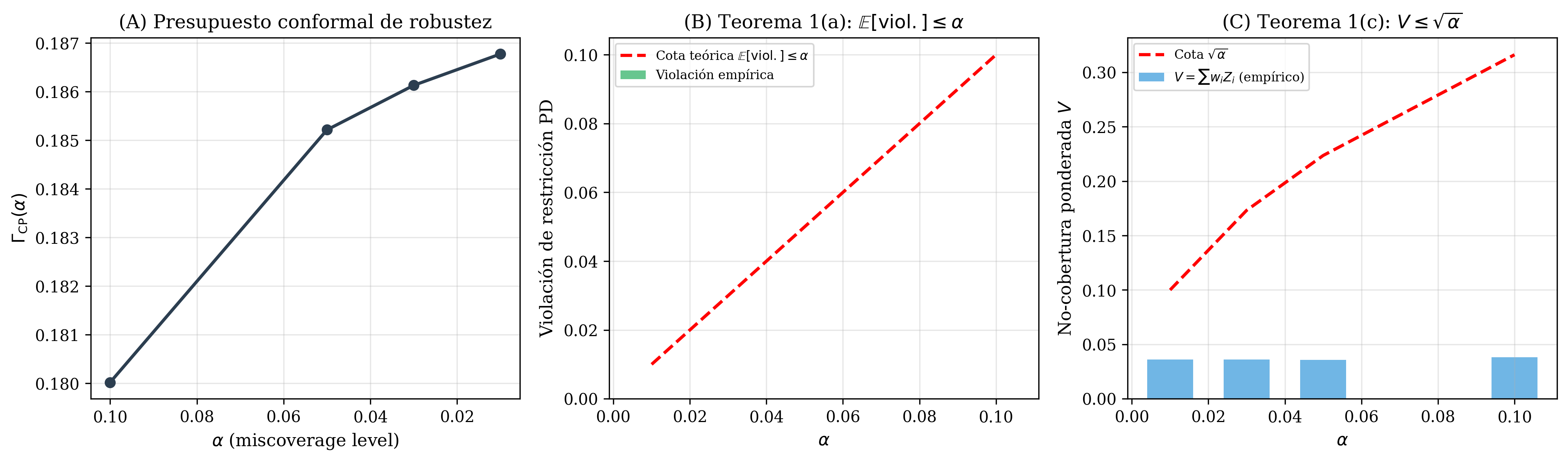
La Figura 5.2 muestra la validación empírica del vínculo teórico en 8 niveles de \(\alpha\). Para una asignación fija, la prp-monotonicity implica que \(\Gamma_{\text{CP}}\) crece cuando \(\alpha\) decrece. En la figura del cierre exacto, el optimizador se reevalúa con la policy promovida, de modo que los pesos también pueden cambiar; la curva observada debe leerse como consistencia empírica de la frontera \(\alpha \rightarrow \Gamma_{\text{CP}} \rightarrow V\), no como una prueba adicional de monotonicidad. La cobertura empírica se mantiene por encima del target nominal en todos los niveles. Sin embargo, la lección final del proyecto es que esa validación, por sí sola, todavía no basta para la afirmación más exigente del paper: hace falta además que el portfolio promovido convierta ese presupuesto conformal en un funded set exacto y defendible.
prp-monotonicity. Panel B: tasa de violación empírica del constraint de PD ponderado vs. cota teórica \(\alpha/\sqrt{\alpha}\) — la violación es cero en todos los niveles. Panel C: miscoverage ponderada \(V\) vs. cota \(\sqrt{\alpha}\) del thm-conformal-feasibility(c) — todos los niveles satisfacen \(V \leq \sqrt{\alpha}\).
Qué valida el refresh exacto y qué valida el cierre 276k
Conviene separar dos piezas empíricas que cumplen roles distintos:
- el refresh exacto 5k mostró que el canónico y el conformal-only seguían fallando el punto más exigente (
alpha = 0.01), y permitió aislar la palanca correcta: el problema residual estaba en la composición del funded set, no en “más conservadurismo conformal ciego”; - el cierre 276k full OOT mostró algo más fuerte: una vez rediseñada la policy, aparece una región robusta completa donde todas las políticas evaluadas pasan exactamente
alpha = 0.01.
En otras palabras: el refresh exacto diagnosticó el cuello de botella; la mini-grid 276k lo resolvió.
El certificado exacto que debe quedar visible en el cuerpo IJDS es pequeño:
| \(\alpha\) | \(\Gamma_{\text{CP}}\) | \(V(\alpha)\) | \(\sqrt{\alpha}\) | violation |
pass |
|---|---|---|---|---|---|
| 0.01 | 0.187987 | 0.028875 | 0.10000 | 0.00000 | sí |
La cota \(\alpha/t\) del thm-conformal-feasibility es teóricamente correcta, pero para varios valores de \(t\) resulta demasiado floja para ser la señal operativa principal. En la práctica, el cierre final del proyecto se ordena mejor con:
weighted_miscoverage_V,gamma_cp,violation,all_bounds_hold,- y, sobre todo, con la composición exacta del funded set.
La contribución empírica fuerte del proyecto no es “la tabla Markov luce apretada”; es que el teorema terminó organizando la búsqueda de una policy exacta, trazable y defendible.
Interpretación práctica
El thm-conformal-feasibility traduce la garantía estadística del intervalo conformal en una garantía operativa sobre el portafolio. La tabla siguiente recuerda la escala teórica general:
| Nivel conformal \(\alpha\) | Violación esperada | \(\mathbb{P}(\text{PD pond.} > \tau + 0.05)\) | \(\mathbb{P}(\text{PD pond.} > \tau + \sqrt{\alpha})\) |
|---|---|---|---|
| 0.20 | \(\leq 0.20\) | \(\leq 1.00\) | \(\leq 0.447\) |
| 0.10 | \(\leq 0.10\) | \(\leq 1.00\) | \(\leq 0.316\) |
| 0.05 | \(\leq 0.05\) | \(\leq 1.00\) | \(\leq 0.224\) |
| 0.01 | \(\leq 0.01\) | \(\leq 0.20\) | \(\leq 0.100\) |
En lenguaje de comité de riesgos: con \(\alpha = 0.10\), el target de riesgo ponderado del portafolio excede el techo \(\tau\) por más de \(\sqrt{0.10} \approx 0.316\) con probabilidad menor al 31.6%. Para \(\alpha = 0.01\), la misma violación se reduce a probabilidad menor al 10%. La cota es conservadora (basada en Markov, sin supuestos distribucionales), lo cual es consistente con el espíritu distribution-free del enfoque conformal. Pero la lectura editorial correcta del proyecto es todavía más concreta: cuando la cota \(\alpha/t\) se vuelve vacua para \(t\) pequeños, la señal útil pasa a ser cómo se comportan V, gamma_cp y violation sobre el funded set realmente promovido.
La novedad empírica del cierre final es esta: el canónico monotónico y el conformal-only todavía no cerraban el punto alpha = 0.01, mientras que el carril portfolio_bound_aware sobre el conformal winner sí lo hace, y además no con un único punto aislado sino con una región completa de políticas exactas.
Lemma 1: tightening condicional bajo independencia adicional
Lema 5.1 (Tightening condicional del bound de factibilidad) Manteniendo los supuestos del thm-conformal-feasibility, sea \(Z_i=\mathbf{1}\{Y_i>u_i\}\) y \(V=\sum_i w_i Z_i\). Condicional en el conjunto de calibración y en una asignación \(x^*\) fijada antes de observar los labels evaluados, suponga además que los \(Z_i\) son independientes y que \(\mathbb{E}[Z_i\mid\mathcal{F}_{cal}]\leq \alpha_i\). Defina \(\mu_w=\sum_i w_i\alpha_i\), \(\sigma_w^2=\sum_i w_i^2\alpha_i(1-\alpha_i)\) y \(w_{\max}=\max_i w_i\). Entonces, para cualquier \(s>0\):
\[ \mathbb{P}\!\left(V \geq \mu_w+s \mid \mathcal{F}_{cal}\right) \leq \exp\!\left(-\frac{2s^2}{\sum_i w_i^2}\right) \tag{5.5}\]
y, con Bernstein,
\[ \mathbb{P}\!\left(V \geq \mu_w+s \mid \mathcal{F}_{cal}\right) \leq \exp\!\left( -\frac{s^2}{2\left(\sigma_w^2+w_{\max}s/3\right)} \right). \tag{5.6}\]
Por la descomposición del thm-conformal-feasibility, esto implica una cota condicional análoga para \(\mathbb{P}(\sum_i w_iY_i>\tau+\mu_w+s\mid\mathcal{F}_{cal})\).
Demostración. Condicional en \(\mathcal{F}_{cal}\) y en \(x^*\), las variables \(w_iZ_i\) son independientes y están acotadas en \([0,w_i]\). La primera desigualdad aplica Hoeffding a la suma ponderada \(V\) y usa \(\mathbb{E}[V\mid\mathcal{F}_{cal}]\leq\mu_w\). La segunda aplica Bernstein con varianza condicional acotada por \(\sigma_w^2\) y rango máximo \(w_{\max}\). La transferencia a la violación del portafolio sigue de \(\sum_i w_iY_i\leq\tau+V\) cuando \(\sum_i w_iu_i\leq\tau\). \(\square\)
El Lemma 1 no reemplaza el thm-conformal-feasibility. Markov sigue siendo la garantía distribution-free principal porque solo requiere control de \(\mathbb{E}[V]\). Hoeffding/Bernstein son útiles para una versión journal más fuerte, pero dependen de independencia condicional de los indicadores de no cobertura, supuesto que split conformal no garantiza estrictamente porque todos los préstamos comparten la misma muestra de calibración.
El apéndice de dependencia docs/research/crpto_conditional_tightening_appendix_2026-05-04.md fija la regla editorial para no sobreprometer este resultado: Markov es el claim principal, mientras Hoeffding/Bernstein quedan como tightening condicional bajo independencia adicional o bajo una futura prueba de concentración con dependencia controlada.
Corolario 1: Precio de la robustez
Corolario 5.1 El precio de la robustez \(\text{PoR}(\alpha) = (Z^* - Z^*_{\text{rob}})/Z^*\) satisface, aproximadamente:
\[ \text{PoR}(\alpha) \lesssim \frac{\Gamma_{\text{CP}}(\alpha) \cdot \overline{LGD}}{\bar{r}} \tag{5.7}\]
donde \(\bar{r}\) es el retorno neto promedio por unidad de exposición. A menor \(\alpha\), \(\Gamma_{\text{CP}}\) crece y el precio aumenta.
Este corolario formaliza la observación empírica del proyecto: el price of robustness no es un accidente numérico, sino una consecuencia directa del presupuesto conformal \(\Gamma_{\text{CP}}\) evaluado en el funded set efectivo. La versión final del proyecto muestra además que ese precio puede reducirse al mismo tiempo que mejora la tightness del bound si el funded set se rediseña correctamente.
Corolario 2: Refinamiento Mondrian
Corolario 5.2 Bajo predicción conformal Mondrian con grupos \(\{g_1, \dots, g_G\}\), la cota del thm-conformal-feasibility se refina a:
\[ \mathbb{E}[V] \leq \sum_{g=1}^{G} \left(\sum_{i \in g} w_i\right) \cdot \alpha_g \tag{5.8}\]
donde \(\alpha_g \leq \alpha\) para cada grupo con \(n_g \geq n_{\min}\) (tamaño mínimo de calibración).
El refinamiento Mondrian tiene una lectura directa: los grupos con mayor soporte muestral de calibración (grades A, B, C con miles de observaciones) logran cobertura más ajustada que el target nominal, reduciendo \(\alpha_g\) por debajo de \(\alpha\). Esto significa que el presupuesto de robustez se distribuye de forma no uniforme: los segmentos bien representados contribuyen menos al costo de robustez, mientras que los segmentos con menor soporte consumen una fracción mayor del presupuesto. En el cierre final del proyecto esta idea reaparece de forma más fuerte: la región robusta completa del 276k muestra que, una vez corregida la composición del funded set, el refinamiento Mondrian ya no solo mejora cobertura por grupo, sino que también vuelve exacta la capa portfolio-aware del teorema.
5.0.5 Relación con decision-focused learning
El marco CRPTO dialoga directamente con SPO+ y la literatura de decision-focused learning. La diferencia central es filosófica y tiene consecuencias prácticas medibles:
- SPO+ entrena end-to-end para minimizar regret de decisión. En este proyecto, el artefacto local A19/Figura 15 reporta una reducción de regret del
49.09%sobre el two-stage clásico (0.425896a0.216837, Wilcoxonp = 1.39e-164); el closeout PyEPO 1.3.7 curado reporta48.51%bajo un protocolo pareado separado (0.358073a0.184366, 5 seeds, 1,000 observaciones, Wilcoxonp = 3.80e-163). Su fortaleza es la eficiencia decisional. - CRPTO protege la decisión a partir de una cuantificación explícita de incertidumbre con garantías distribution-free. Su fortaleza es la auditabilidad: score monotónico, calibración Venn-Abers, cobertura verificable, estabilidad por grupo, y trazabilidad completa para reguladores (SR 11-7).
El trade-off es concreto: CRPTO paga un precio de auditabilidad en regret (su policy worst-case es más conservadora que la de SPO+), pero a cambio obtiene garantías formales que SPO+ no puede ofrecer — un auditor puede verificar la cobertura empírica del conjunto de incertidumbre, pero no puede verificar si el regret de SPO+ se mantendrá estable bajo cambio de régimen.
Los enfoques no son incompatibles. De hecho, una agenda de integración natural sería incorporar la pérdida SPO+ como objetivo de entrenamiento del modelo base mientras se mantiene el wrapper conformal para la capa de decisión. El paper los presenta como comparadores complementarios que iluminan diferentes dimensiones del problema.
5.0.6 Posicionamiento en el marco universal de Powell (SDAM)
El pipeline CRPTO puede clasificarse rigurosamente dentro del Universal Modeling Framework para problemas de decisión secuencial propuesto por Powell (2026). Powell organiza cualquier problema de decisión bajo incertidumbre en cinco elementos canónicos: estado (\(S_t\)), decisión (\(x_t\)), información exógena (\(W_{t+1}\)), función de transición (\(S^M\)) y función objetivo (\(C(S_t, x_t)\)). Sobre esa base, clasifica toda política de decisión en cuatro meta-clases universales: Policy Function Approximations (PFA), Cost Function Approximations (CFA), Value Function Approximations (VFA) y Direct Lookahead Approximations (DLA).
Mapeo de los cinco elementos
La Tabla 5.5 presenta el mapeo entre los elementos SDAM y su instanciación concreta en nuestro pipeline.
| Elemento SDAM | Notación | Instanciación en el proyecto |
|---|---|---|
| Estado \(S_t\) | \(S_0 = (X_{\text{feat}}, B, \tau, [\hat{p}_i, \ell_i, u_i])\) | Covariables de los préstamos OOT, presupuesto \(B\), límite de PD \(\tau\), intervalos conformales Mondrian |
| Decisión \(x_t\) | \(x_0 \in [0,1]^n\) | Vector de asignación: fracción de cada préstamo a financiar |
| Información exógena \(W_{t+1}\) | \(W_1 = (y_{\text{true},1}, \dots, y_{\text{true},n})\) | Defaults reales observados en el período OOT (2018–2020) |
| Función de transición \(S^M\) | \(S_1 = S^M(S_0, x_0, W_1)\) | Cálculo del P&L realizado del portafolio dados los defaults observados |
| Métrica de contribución \(C(S_t, x_t)\) | \(\sum_i x_i [r_i - p_i^{\text{eff}} \cdot \text{LGD}]\) | Retorno neto menos pérdida esperada ajustada por incertidumbre |
Clasificación como política CFA
La distinción más importante del framework SDAM para nuestro caso es la clasificación de la política. Powell define una CFA como una política que resuelve un problema de optimización que es una simplificación del problema original, con parámetros introducidos para mejorar el desempeño bajo incertidumbre. Nuestro LP robusto es exactamente eso:
- El problema original (intratable) sería un programa estocástico que enumera todas las \(2^n\) realizaciones posibles de default y optimiza en esperanza sobre ellas — una instancia de DLA en la taxonomía de Powell.
- Nuestra simplificación CFA reemplaza esa distribución completa por la cota superior conformal \(u_i(\alpha)\), resolviendo un LP determinista cuya restricción de pérdida incorpora la incertidumbre de forma paramétrica.
- Los parámetros de política \(\theta = (\alpha, \gamma, \tau)\) — nivel conformal, aversión a incertidumbre, y tolerancia de riesgo — no existen en el problema estocástico original; son artefactos de la aproximación CFA que permiten controlar el trade-off retorno-robustez.
El barrido sobre \(\alpha \in \{0.01, \dots, 0.20\}\) con evaluación en el dataset OOT constituye policy search en la terminología de Powell: simulamos la política \(X^\pi(S_0|\theta)\) sobre el sample path histórico \(\omega\) (defaults 2018–2020) para encontrar la combinación de parámetros que maximiza el retorno ajustado por riesgo.
Diferenciación respecto a las otras clases de política
La clasificación CFA es deliberada y distingue nuestro enfoque de las alternativas:
- No es PFA (regla analítica simple): no usamos un umbral fijo tipo “rechazar si PD > 0.15”. La decisión emerge de resolver un LP completo con restricciones de presupuesto, concentración y PD.
- No es VFA (función de valor aproximada): no estimamos el valor futuro de un estado de portafolio para guiar la decisión actual, como haría un enfoque de approximate dynamic programming.
- No es DLA (programación estocástica): no optimizamos sobre escenarios simulados del futuro mediante Monte Carlo o programación multi-etapa. En particular, la distinción con DLA es operativamente crucial: una DLA requeriría generar miles de escenarios de default, resolver un programa estocástico masivo y actualizar iterativamente — un costo computacional que además dificulta la auditabilidad del proceso decisional.
La ventaja de la CFA es triple: es determinista (un LP resuelto una vez con HiGHS en milisegundos), auditable (el regulador puede inspeccionar la restricción \(\sum w_i u_i(\alpha) \leq \tau\) directamente) y matemáticamente fundamentada (la garantía de cobertura conformal del thm-conformal-feasibility se hereda a la restricción de forma verificable).
La formulación actual es estrictamente uniperiodo (\(T = 1\)): se toma una decisión de asignación y se observa un único vector de defaults. Esto es el caso más simple del framework SDAM, donde la función de transición \(S^M\) es trivial (calcula P&L) y no hay secuencia de decisiones adaptativas. La riqueza secuencial del framework — actualización de creencias \(B_t\), evolución de recursos \(R_t\), encadenamiento de decisiones — queda latente y se activa en la extensión a producción (véase Sección 9.0.8).
Interpretación de \(\alpha\) como parámetro de sintonización de política
A diferencia de los parámetros de penalización en optimización robusta clásica — que se calibran por convención o juicio experto — el nivel conformal \(\alpha\) tiene una semántica estadística directa: controla la probabilidad de no cobertura del intervalo predictivo. Esto significa que el parameter tuning de la CFA no es heurístico sino que está anclado a una garantía distribution-free sobre la información exógena \(W_{t+1}\). En el lenguaje de Powell, \(\alpha\) es un tunable parameter cuyo efecto sobre la contribución \(C(S_t, x_t)\) puede cuantificarse formalmente a través del thm-conformal-feasibility y el cor-por.
5.0.7 Hipótesis defendible
La hipótesis que el resto del paper pone a prueba es concreta:
En crédito minorista real, un conjunto de incertidumbre conformal puede ofrecer mejor equilibrio entre garantía y accionabilidad que baselines clásicos más anchos o menos estables por grupo.